NICT(国立研究開発法人情報通信研究機構)は4日、日本語のWebテキストのみを用いた生成系大規模言語モデルの開発を発表した。
独自に収集した350GBの日本語Webテキストを使用し開発したモデルは、パラメータ数400億のLLM(Large Language Model)で、事前学習済みのモデルを別のデータで追加学習するファインチューニング等は行っていないものの、UIを含め約4カ月で開発を完了し日本語でのやり取りが可能な水準に到達している。現状では、ChatGPTとは比較できるレベルではないとしながらも、各種質問への回答や要約、論文要旨の生成、翻訳などが可能で、存在しない映画のあらすじなどハルシネーションの生成も例示している。
-
プロトタイプの動作例(NICT資料より)


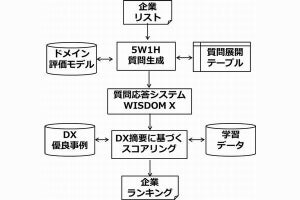
NICTでは、2015年から大規模Web情報分析システムWISDOM Xを試験運用しており、2021年からはBERTを取り入れた深層学習版として公開し日本語による質問/回答の機能を提供しているが、今後はWISDOM Xの質問応答用データを活用したファインチューニングなどで改善を図るとともに日本語を中心とした大規模化を目指す予定で、GPT-3と同規模1,790億パラメータのモデルの事前学習に取り組んでいることも発表している。