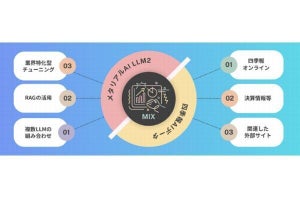
アドビは10月13日、PDFから文書構造を維持したままに構造分析を行える「Adobe PDF Extract API」が三菱UFJトラスト投資工学研究所に導入されたことを発表した。
PDF Extract APIは、資料価値のあるPDFファイルからテキストや画像などを抽出できるAdobe Document Serviceのひとつで、構造化されたデータのまま大量のPDFファイルを解析できる機能を提供する。AdobeのWebサイトには、実際のPDFでJSON、PNG、CSV形式でアウトプットするデモも用意されており、PDFファイルの構造やテキストをJSONで出力し、フォルダに画像ファイルやCSVファイルを出力している。
-
「Adobe PDF Extract API」のデモサイト

PDF Extract APIを導入したのは、日本初の金融工学に特化したシンクタンクとして設立された三菱UFJトラスト投資工学研究所。同社は、三菱UFJフィナンシャル・グループ(MUFG)の研究所として、膨大なデータを収集・分析しているが、PDFファイルも重要なデータになる。各社の決算報告書をはじめ、重要な報告書をPDFファイルで提供する企業も多い。同社では、PDF Extract APIの導入によりこれまで、目視での確認を要していた900にもおよぶPDFの統合報告書から、テキストデータの抽出を3日で完了させている。三菱UFJトラスト投資工学研究所 研究部 開発第2グループの成富佑輔氏は、"分析にあたってPDFから正確な情報を構造データを損なうことなく抽出することは必要不可欠"とその有用性を述べている。