Armの日本法人であるアームは9月15日、記者会見を開き、インフラストラクチャ(サーバ)向けCPU IP「Neoverse」のロードマップを更新。これまで「Demeter」(開発コード名)と呼んできたCPU IPをパフォーマンス重視の「Neoverse Vシリーズ」の次世代IP「Neoverse V2プラットフォーム」として、正式提供を開始したことを明らかにした。
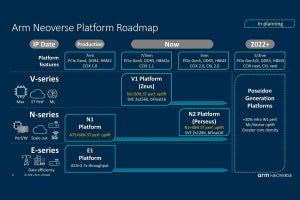
3シリーズあるNeverseがいずれも第2世代に
Vシリーズは2020年に、バランスを取ったスケールアウト志向の「Nシリーズ」、消費電力やコストを最小限に抑えた「Eシリーズ」に続く、HPCなどのパフォーマンスを必要とするニーズに対応したラインナップとして登場。Neoverse V2は、そのVシリーズの最新版に位置づけられるCPU IPで、クラウドとHPCのワークロードの分野で求められる整数演算性能を提供するほか、Armv9アーキテクチャに基づく複数のセキュリティ強化機能を提供するとしている。
Neoverseシリーズのそれぞれの位置づけと今回更新されたNeoverseシリーズのロードマップ。すでにN2とE2は発表済み (資料提供:Arm)


現在、ArmアーキテクチャはエッジのIoT分野からネットワーク(5G)、クラウド、HPCまで対応可能なエコシステムを構築し、すべての領域をArmアーキテクチャでサポートすることを可能としている。Neoverseは、クラウド、HPC領域での活用を意識したIP製品群で、当該分野のクラウドベンダやHPCメーカーなどからのフィードバックをもとに次世代の仕様を決定しており、クラウドのワークロードに必要な性能や機能、消費電力の最適化などを図ってきたという。そうした甲斐もあり、2022年はNeoverseの採用がクラウドや5G分野で進んでいるほか、NVIDIAがGrace CPUにNeoverse V2を採用するなど、新たな動きも出てきたとする。
もともと低消費電力を売りにしてきたArmアーキテクチャ。2005年にCortexブランドを発表する以前のARM7やARM9などの時代から組込機器や携帯電話(スマートフォン以前)などで活用されてきており、世代を追うごとの性能向上に伴い、適用領域を拡大してきた。2022年はクラウドや5G分野におけるNeoverse採用の大きな話題がいくつも出てきており、NVIDIAのGrace CPUによるNeoverse V2の搭載もそうした1つのトピックスとなる (資料提供:Arm)


ユーザーニーズを受け止めて性能・機能向上が図られたNeoverse V2
Neoverse V2もそうしたニーズを汲む形で開発されてきたIPで、主にクラウドワークロードの性能向上、消費電力とシリコン面積との適切なバランスにおいてのシングルスレッド性能向上、ハイペースで進められるIP開発への対応といった3点への対応を重視したとするほか、Armv9アーキテクチャによるハードウェアセキュリティ機能の強化も実現されている。
そうした中でもクラウドワークロード性能の中でもっとも要求が高かったのはIntegerの性能向上であったという。Neoverse V2では、マーケットリーダーレベルのパフォーマンスを実現したとするほか、スケーラビリティや電力効率の向上も実現。低消費電力化が進めば、搭載コア数を増やせるため、結果的にシステムコストの低減を図ることができるようになるとする。
また、最近のクラウドアプリケーションでは、膨大なデータセットの処理が必要になるので、データをできるだけCPUの近くに物理的に置くことが電力効率の向上につながるため、コアごとにV1比で2倍の2MBのプライベートL2キャッシュを設けることを可能としたという。
さらに、行列演算性能についても、 従来のSVE(Scalable Vector Extension:スケーラブルベクタ拡張)から発展形となるSVE2へとアップグレードを実施。マシンラーニング処理性能が向上された(ベクタエンジンについては4レーン128ビットレジスターを搭載し、これの処理に最適化されたマクロアーキテクチャのサポートも搭載したとする)ほか、BF16(Bflot16)やINT8を用いた演算も可能としたとする。
-
Neoverse V2の概要 (資料提供:Arm)

加えて、システムレベルで見ても、高いバンド幅がバスに対して求められるようになることから、Neoverse N2で培ったCash Coherent Mesh NetworkやMMUやGCIなどのシステムIPを組み合わせることでニーズに対応したとするほか、CMN-700インターコネクトにおいては前世代比で4倍となる最大512MBのシステムレベルキャッシュ(SLC。ラストレベルキャッシュとも)の搭載を可能としたとのことで、コア当たりのキャッシュ容量も増やせることになり、クラウドネイティブのワークロード性能向上につなげているとする。
-
システムレベルで見た場合のNeoverse V2の概要 (資料提供:Arm)

このほか、CXL(Compute Express Link)2.0にも対応したとしているが、同社ではUCIeとCXLの両方に参加しており、それらをつなぐものとして、標準バス規格の最新世代となるAMBA CHI(アンバチャイ)に適合させるためのIPであるCMN(Core Mesh Network)の開発も同時並行して進めているという。
-
CXLとUCIeをつなぐためのIPの開発も進めているとする (資料提供:Arm)

すでに複数のメーカーがNeoverse V2を用いた半導体設計を開始
なお、同社ではNVIDIAのGraceへのNeoverse V2の採用以外にも、すでに複数のメーカーでプロセッサの設計が開始されているとしており、2023年にはそうした次世代プロセッサが登場し、例えばGraceでは、スレッドあたりのInteger処理性能、ソケットあたりのInteger処理性能ともに、2023年に登場するであろうx86アーキテクチャの次世代プロセッサと比べても高い性能を提供できるとしている。
-
Traditionalとしているのはx86アーキテクチャのCPU。現状のNeoverse採用SoCの段階ですでにx86 CPUよりもスレッドあたりでも、ソケットあたりでも高い性能を出しているSoCが複数存在しているが、同社の見立てでは、2023年にはGraceの登場により、その差が開くことになるとしている (資料提供:Arm)

また、同社ではすでにCXL 3.0やPCIe Gen6などに対応する次世代Nシリーズの開発も進めているとのことで、2023年にはパートナーへの提供を開始できる見通しだとしている。