日本ヒューレット・パッカード(HPE)は5月25日、オンラインで記者説明会を開き、大規模な機械学習モデルを構築・トレーニングするためのターンキーソリューションである「HPE Machine Learning Development System」と、データプライバシーを維持しつつAIモデルの学習結果を共有・統合することが可能な「HPE Swarm Learning」の提供開始を発表した。
AIの実運用までカバーする「HPE Machine Learning Development System」
AI開発のためのHPE Machine Learning Development Systemは、機械学習ソフトウェア基盤、コンピュート、アクセラレータ、ネットワーキングを統合したエンドツーエンドソリューションで、高精度なAIモデルを迅速かつ大規模に開発・トレーニングすることを可能としている。
-
「HPE Machine Learning Development System」の概要

日本ヒューレット・パッカード AIビジネスデベロップメントマネージャー 山口涼美氏は、モデル開発とトレーニングの課題として「良いモデルの作成のためにさまざまな組み合わせを施策・実行し、多くのコード生成・結果の可視化が必要となることから、管理が煩雑になる。また、チームで効率的なGPUリソースを利用するためコストと時間を要し、環境やツールの多様性、変化、依存性、複雑性、セキュリティの担保が必要になる。そして大量のデバックとコーディングの負担がかかる」と指摘。
-
日本ヒューレット・パッカード AIビジネスデベロップメントマネージャー 山口涼美氏

同社は、昨年6月にオープンソースのAIトレーニング基盤を手掛けるDetermined AIを買収し、HPEのHPC&AIソリューションと組み合わせて提供することを発表しており、HPE Machine Learning Development SystemはAIに特化したソリューション。
Determined AIによるAIトレーニング基盤は「HPE Machine Learning Development Environment」という名称で、新ソリューションに含まれ、機械学習モデルの構築とトレーニングに利用することで、成果を得るまでに要していた数週間あるいは数カ月を、数日に短縮することができるという。
また、新ソリューションはソフトウェアに加え、アクセラレータなどの特化型コンピューティング、ネットワーク、サービスを組み合わせており、AIインフラの導入に伴う複雑性を回避できるよう支援するとともに、最適化された機械学習モデルの構築とトレーニングを大規模かつ効率的に、すぐに開始すること可能。モデルの精度を向上させるにあたり、機械学習アルゴリズムの鍵となる分散学習、自動化されたハイパーパラメータの最適化、ニューラルアーキテクチャの探索を可能としている。
さらに、32GPUの小規模構成から256GPUの大規模構成まで、さまざまなワークロードに対してモデルを効率的に拡張するための主要なパフォーマンスドライバーである、最適化されたコンピュート、アクセラレータ、インターコネクトを提供する。
32GPUの小規模構成においては、自然言語処理(NLP)やコンピュータービジョンなどのワークロードに対して、約90%のスケーリング効率を実現。社内で実施したテストの結果として、32個のGPUを搭載した新ソリューションは、同じGPUを32個搭載した最適化されていないインターコネクトの別製品と比べて、NLPワークロード全体にわたって最大5.7倍の処理速度を実現しているという。
そのほか、統合ソリューションとして大規模なモデル開発とトレーニングをターンキーで行うための、事前設定済みのフルインストールされたAIインフラストラクチャを提供。一環として、HPE Pointnext Servicesがオンサイトでのインストールとソフトウェアのセットアップを実施し、ユーザーは機械学習モデルの実装とトレーニングをすぐに開始して、データから高精度のインサイト(洞察や知見)をより得ることを可能としている。
新ソリューションの小規模な構成としては、機械学習基盤がHPE Machine Learning Development Environment、AIインフラストラクチャはAIモデルのトレーニングと最適化のための大規模な専用コンピューティング機能を「HPE Apollo 6500 Gen10 Plus System」が提供し、アクセラレータは8個の「NVIDIA A100 80GB GPU」で構成可能。
集中監視と管理は、クラスタを管理するための高度なセキュリティを備えたシステム管理ソフトウェアソリューションである「HPE Performance Cluster Manager」で行う。システムコンポーネントの制御と管理のための管理スタックは「HPE ProLiant DL325サーバ」と「1Gb Ethernet Aruba CX 6300スイッチ」を使用する。また、ネットワークは「NVIDIA Quantum InfiniBand ネットワーキングプラットフォーム」を使用する。
-
「HPE Machine Learning Development System」の構成

AIモデルの学習結果を共有・統合する「HPE Swarm Learning」
HPE Swarm Learningはデータを保護しながらAIモデルの学習結果を共有・統合することができ、医療やクレジットカード詐欺の検出など、エッジでのインサイトを可能にするAIソリューション。
同ソリューションは非中央集権型の機械学習をエッジあるいは分散した拠点で利用可能にするフレームワーク。HPE swarm APIでAIモデルとの統合が容易なコンテナとして提供し、ユーザーは実際のデータではなく、AIモデルの学習結果を組織の内外と随時共有し、トレーニング効果を高めることができる。
-
「HPE Swarm Learning」の処理の流れ

山口氏は「データを移動させずにパラメータを参加ノード間で共有して、許可制のブロックチェーンで中央管理が不要なPeer to Peer Netwarkを使用し、データサイロを超えた共同の機械学習が可能だ」と、メリットを説明する。
分散されたデータを同一のソースで利用することを可能とし、データガバナンスとプライバシーを継続しながら、トレーニング用データセットを増やし、偏りのない方法で学習する機械学習モデルを構築することが可能。
さらに、利用メンバーの安全な追加、リーダーの動的な選出、モデルパラメータの結合にあたり、ブロックチェーン技術を用いることで、データそのものではなく、エッジで得た学習結果のみが共有される。学習結果のみを共有するため、ユーザーはプライバシーを損なうことなく大規模なトレーニングデータセットを活用でき、バイアスを解消してモデルの精度を向上させることを可能としている。
例えば、病院では画像記録やCT、MRIスキャン、遺伝子発現データから学習結果を得て、病院間で共有することで、患者情報を保護しつつ、病気などの診断の向上に役立てることができる。また、銀行や金融機関はクレジットカード詐欺に関する学習結果を複数の金融機関で共有することが可能。
-
「HPE Swarm Learning」のスタック

製造現場では予知保全で機器を修理する必要性を事前に把握し、故障に起因するダウンタイムを防止することに役立てることができるほか、保守管理者は複数の製造現場のセンサデータから収集された学習結果からインサイトを得ることを可能としている。
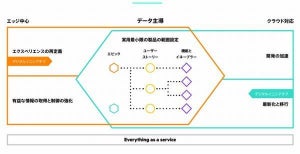
データファーストモダナイゼーションを提唱するHPE
HPEでは、データファーストモダナイゼーションを提唱しており、その前段階の第一波としてインフラストラクチャファーストを掲げ、インフラのモダナイゼーションやサイロ化したITの管理、プロセスのデジタル化、迅速なデプロイメント、クラウドファーストをポイントとしていた。
そして、第二波がデータファーストとなり、データ中心のモダナイゼーション(近代化)やEdge to Cloudの統合サービスの提供、新たな体験の提供、スピーディな意思決定、データ資産のコントロールをキーワードとしている。
日本ヒューレット・パッカード HPC&AI・MCS事業統括 執行役員の根岸史季氏は「データの流れを理解し、流れに沿って最適化していくことがデータファーストだ。なぜならば複数のシステムやサービスを組み合わせていくと、つなぎ目を確実に実装することで意思決定を素早くすることが重要になるからだ。課題があるから、ソリューションがあるというわけではなく、そもそもの課題を定義して必要なさまざなサービス・ソリューションをポートフォリオとして備えていくという考え方がキーとなる」と強調した。
-
日本ヒューレット・パッカード HPC&AI・MCS事業統括 執行役員の根岸史季氏

また、同氏はこのような考え方をAI・機械学習の文脈としてとらえると、いきなり大規模で実装するのは無謀であると同時に現実的ではないという。そのため、まずは小規模で実証・検証したうえで、実現可能性が見えてきたら開発・運用を定義してチームとして利用し、本番運用で大規模化していくことが望ましいとしている。
このような状況に対して、同社では従来からAI/ML(マシンラーニング)プラットフォームとして、AIスターター・教育向けソリューション、コンテナプラットフォーム・MLOps向けソリューション、ビッグデータ・統合分析基盤向けソリューションを提供していた。今回、これらのポートフォリオに大規模並列学習・HPC&AI向けソリューションとしてHPE Machine Learning Development System、エッジ学習向けソリューションとしてHPE Swarm Learningを加える形となった。
-
HPEにおけるAI/MLプラットフォームのポートフォリオ