東京工業大学(東工大)は5月12日、レンズレスカメラの画像処理を高速化し、高品質な画像を取得できる、機械学習技術「Vision Transformer」(ViT)を用いた新たな画像再構成手法を開発したことを発表した。
同成果は、東工大 工学院 情報通信系のPan Xiuxi大学院生、同・Chen Xiao大学院生、同・武山彩織助教、同・山口雅浩教授らの研究チームによるもの。詳細は、光学およびフォトニクスに関するすべての分野を扱う学術誌「Optics Letters」に掲載された。
近年のスマートフォンに加え、IoT機器の普及に伴い、カメラの小型化、軽量化、低価格化への要求が高まっており、そうしたニーズに対応することを目的に、画像撮影過程の一部を光学ハードウェアからコンピューティング技術に置き換えることで、レンズ光学系を簡素化する「レンズレスカメラ」への注目が集まっている。
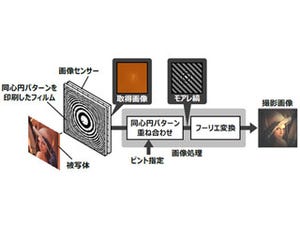
レンズレスカメラにおいては、被写体から発せられた光がシート状の特殊なマスクを通して符号化され、センサー上にパターンとして投影される。このパターンは人間の目には理解できないが、光学系の特性を数値的にモデル化することで復号できるほか、数学的処理の手法を変えることで、撮影後にピントを自在に変えるリフォーカスなども可能だという。レンズレスであるため、マスクとセンサーを半導体プロセスで一体的に作製することも可能なほか、超小型化によって今までにない新しいアプリケーションを実現することも期待されている。
しかし、レンズレスカメラ技術の実用化に向けては、画像再構成技術に基づく復号処理に課題が残されているという。これまで用いられてきた復号処理には、(1)モデルに基づく復号法、ならびに(2)機械学習を用いた手法があるが、モデルに基づく復号法では、物理モデルを精度よく近似することが難しく、画像の品質が低下しやすいほか、最適化問題を解く必要があるため、処理時間が長いという課題があった。
一方の機械学習の場合は、一般的に画像再構成に用いられる畳み込みニューラルネットワーク(CNN)が、隣接した画素同士の相互関係を主に学習するのに対して、レンズレス光学系では画像上の広い範囲の相互関係を学習しなければならないため、効率的な処理ができず、十分に高品質な画像を得られないという課題を抱えていたという。
-
レンズレスカメラの仕組み (出所:プレスリリースPDF)

そこで研究チームは今回、マスクを用いたレンズレス光学系の物理モデルとその特性の考察に基づき、画像再構成のための新しい機械学習アルゴリズムを提案することにしたという。