B2C、B2Bにかかわらず、企業の競争力を維持するには、データの分析や利活用が必要不可欠です。従来はデータ収集にかかるコストが高かったことから、必要なデータを自発的に取得する形で収集する方法しかありませんでした。しかし、クラウドコンピューティング技術の発展やIoTにおけるセンサーデータの普及により、あまり手間をかけずに膨大な量のデータ収集が可能となりました。
これにより、データ分析を通じて、ビジネスにおける迅速な意思決定や新事業の創出が可能になった一方で、日々取り扱うデータ量の増加によって管理プロセスが煩雑化したことにより、情報漏えい等の事故につながるリスクが高まっています。
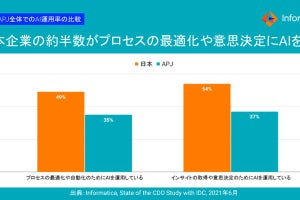
IPA(情報推進機構)が発表した「企業における営業秘密管理に関する実態調査2020」によると、情報漏えいのルートとして最も多いのは、中途退職者(役員・正規社員)による漏えい(36.6%)であり、現職従業員等の誤操作、誤認等による漏えい(21.2%)、現職従業員等のルール不徹底による漏えい(19.5%)と続いています。
-
漏えい発生のルート 資料:IPA「企業における営業秘密管理に関する実態調査2020」

同調査より、情報漏えいは組織内部のデータ管理が大きな要因となっていることが分かります。取り扱うデータ量が増える中、データの種類や機密性などを理解して管理を徹底しなければ、機密情報や個人情報の漏えいリスクを下げることはできません。
そこで本稿では、企業・組織がデータを安全かつ効果的に活用し、情報の漏えいリスクを下げるために気を付けたい3つのポイントを紹介します。
まずはデータの「発見」と「分類」から
データ量が飛躍的に増加し、組織でのデータの活用が当たり前となった一方で、ほとんどの企業は機密データが組織内のどこに格納されていて、誰がそのデータにアクセスできるのかについて、正確に把握しきれていません。このようなデータの可視性の欠如は、データ侵害に対するリスクを増大させます。
このようなリスクを軽減する方法の一つに、組織を横断して機密データや個人データを「発見」し、「分類」するという方法があります。例えば、顧客の満足度を図るための調査等に含まれる個人データがそのまま放置されているケースがあります。また、基幹システムからデータレイク、DWH(データウェアハウス)へデータがコピーされる中で、パスワードや口座番号は匿名化できているのに、住所は匿名化を忘れてしまうなど、「個人情報のデータの匿名化が一部しか行われていない」「匿名化された情報か否かわからない」「どこまで匿名化された情報か判断が付かない」といったケースもあります。
まずは、こうしたデータを社内で「発見」し、それらのデータを「分類」して管理することが重要となります。
一方で、データ量が増えるほど、こうした作業がデータ管理者にとっては負荷となるのも事実です。例えば「住所」というデータ一つとっても、企業が保有する住所にはさまざまな種類があります。顧客の住所と加盟店やサプライヤーの住所があった場合、住所のデータだけでは、すぐに保護すべき顧客の住所かどうかを判断できません。
そこで、データ管理ツールを用いて疑わしいデータを全て特定してタグ付けで分類し、同じ「住所」データとして把握しておきつつ、その後に顧客住所や法人住所などの詳細の分類を行うといった作業ステップを踏むことで、効率的なデータ管理が可能となります。こうした作業は従来、手作業で抽出していましたが、必要なデータの発見や分類において、不正確または最新ではないデータを除外の自動化によって効率化を図ることができます。