KDDI総合研究所は2月28日、画像認識技術で抽出した顔の表情データからAI(Artificial Intelligence:人工知能)で「未来の表情を予測する」技術を開発したことを発表した。同技術を3Dアバターを用いた接客や会議、バーチャルイベントなどに活用することで、現実空間の人のまばたきや口の動きを遅延なく表現できるため、メタバース空間上での快適な体験につながることが期待される。
アバター描画技術には、表情を認識してから3Dアバターに反映するまでにタイムラグが生じる課題がある。また、快適に会話するためには、映像や音声の遅延を0.15秒以内に抑える必要があるという。これに対し同社は、0.2秒後の表情を予測し、常に先読みしてアバター描画する技術を開発したとのことだ。
-
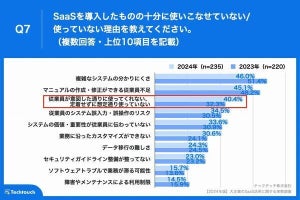
表情予測技術を活用したメタバース上での3Dアバター対話のイメージ

3Dアバターを描画する際の遅延を低減するためには、先読み描画することで遅延を相殺することが有効とされる。しかし、高速な予測処理技術が必要となる上、手や足といった骨格の動作と比較して顔の表情は急激かつ複雑に変化することから、高精度な予測を瞬時に行わなければならなかった。
そこで同社は今回、表情データそのものに加えて、表情データの単位時間当たりの変化量(微分値)を入力データとして捉え、未来の表情データを推定する再帰型ニューラルネットワークの機械学習モデル開発したとのことだ。これにより、機械学習モデルの内部構造を変えることなく、入力データを改良することで、予測処理の負荷を増やさずに複雑な時系列変化に対応できるようになったという。
同技術により、現実空間の人の細かい表情を遅延なく3Dアバターに反映できるようになり、メタバース上でもより対面の感覚に近いインタラクティブなコミュニケーションが実現できると期待される。さらに、同社はスマートフォン向けにフォトリアルな3DアバターのAR配信技術を開発しており、同技術と併用することでよりリアルに感じられる体験の提供を目指す。