NTTテクノクロスは11月12日、音声認識ソフトウェア「SpeechRec Server」の新バージョンを、2021年11月19日から販売開始することを発表した。
-
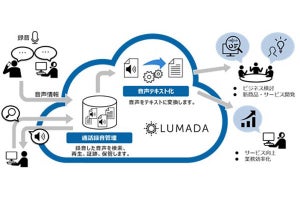
「SpeechRec Server」による音声情報処理のイメージ

「SpeechRec Server」は、音声音響処理、自然言語処理などの情報処理を人間の脳と同じようにオールインワンで可能にするAIを活用した音声認識ソフトウェア。
新バージョンでは、次世代メディア処理AI「MediaGnosis」を活用した音声情報処理として「End-to-End」方式を採用。これまで一部の音声情報処理のみに適用していたディープニューラルネットワーク(DNN)をすべてに適用し、音声データ入力からテキスト出力までをオールインワンで実現したことで、人間の脳と同じように音声から日本語を理解するスムーズな処理が可能となり、音声認識精度がさらに向上したという。
-
「SpeechRec Server」による変換/分類機能のイメージ

相づちや「えー」「あのー」などのつなぎ言葉に加え、「私なんかは」などの話し言葉特有の表現を認識し、話の意味を理解しやすいようなテキストに変換するほか、その情報を内容ごとに分類して表示することも可能だという。さらに、複数の話者が話す場合、話者を識別するために話者の音声を事前登録したり、話者ごとにマイクを分けたりする必要がなく、話者の声質や波形などの特徴から「MediaGnosis」が自動で話者を識別する機能も搭載する。
音声認識結果の変換と分類の処理をオールインワンで実現するため、システムの複雑化やコスト低減につながるとともに、新たなテキスト処理のニーズが出てきた場合には、システム構成を変えずに対応できるということだ。
-
「SpeechRec Server」の話者識別機能(話者ダイアリゼーション機能)イメージ