Hot Chips 33においてIntelは「Ponte Vecchio」を発表した。3D実装で複数のタイルを接続してチップを完成させるという作り方はAMDなどもやっているがアクティブなタイルを46個搭載しているというのは、けた外れで、驚異的に複雑なチップである。
Ponte Vecchioはフィレンツェの観光名所の橋で、筆者は本物を見たことは無いが、写真を見ると、橋の大部分が3~4階建てになっていてそれに増築部分が外に張り出している。そして、橋の内部には多くの宝飾店が軒を連ねているとのことである。

何層ものタイルが積み重なって作られているPonte VecchioチップとフィレンツェのVecchio橋が似ているというところからこの開発コードネームが付けられたのではないかと思う。
-
図1 IntelのHPC向けXeHPCチップは計算性能を500倍に引き上げるのが目標 (このレポートの以下すべての図は、HC33におけるIntelのDavid Blythe氏の発表スライドのコピーである)

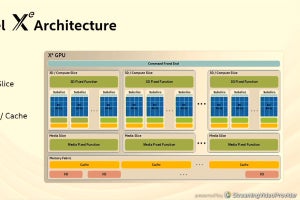
XeHPCはCore、Slice、Stack、Linkという構成ブロックでできている
-
図2 XeHPCはCore、Slice、Stack、Linkという構成ブロックでできている

XeHPCの計算エンジンはXe-Coreである。Xe-Coreは図3に示すように、8個のベクトルエンジンと8個のマトリクスエンジンを搭載している。さらに、計算エンジンにデータを供給したり、演算結果を取り出すためのLoad/Storeと仕様頻度の高いデータを記憶して高速で供給するCacheを持っている。キャッシュはL1キャッシュと512KBのSLM(共有ローカルメモリ)があり、SLMはL1キャッシュとしても使えるようになっている。Load/Storeはメモリとレジスタの間で毎クロック512Bの転送ができる。
そして、ベクトルエンジンは毎サイクル512bit、マトリクスエンジンは毎サイクル4096bitの演算ができる。
-
図3 Xe-CoreはXeHPC GPUの計算用の構成ブロック。Xeコアは8個のベクトルエンジンと8個のマトリクスエンジンを持ち、512B/Clkでロードストアが行える。キャッシュはL1キャッシュ、512KBのSLMとIキャッシュを持っている

ベクトルエンジンはFP32での演算なら毎クロック256演算が出来、FP64でも毎クロック256演算が出来る。一方、FP16の演算であれば2倍の512演算/Clkの演算が出来る。マトリクスエンジンはTF32では2048演算/Clk、FP16かBF16なら4096演算/Clkの計算、Int8なら8192演算/Clkの計算ができる。
-
図4 XeHPCコアのベクトルエンジンはFP32とFP64では毎クロック256演算、FP16では512演算を実行できる。マトリクスエンジンXMXはTF32では2048演算/Clk、FP16とBF16では4096演算/Clk、INT8では8192演算/Clkの演算ができる

そして、16個の計算コアと16個のレイトレーシングユニットと1つのハードウェアコンテクスト処理ユニットを纏めたものがXeHPC sliceである。レイトレースの場合は、レイトレーシングユニットは、光線の追跡や三角形の面と光線の交差点の計算などを行う。
-
図5 XeHPCスライスは16個のXeHPCコアと16個のRay Tracingユニットを持ち、1個のハードウェアコンテキストを実行する

XeHPC stackは4sliceを纏めたもので、それにL2キャッシュや4個のHBM2eコントローラと1個のメディアエンジンが付いている。そして、Stackからは8本のXeリンクが出ている。
-
図6 XeHPCスタック最大4個のスライスとL2キャッシュ、4個のHBM2eコントローラ、1個のメディアエンジンと8本のXeリンクを持っている

Xeリンクは高速、かつコヒーレントにGPU間を接続する伝送路である。Xeリンクは単にLoad/Storeのデータを運ぶだけではなく、バルクのデータの転送を行うことができ、同期の機能も持っている。そして、8ポートのスイッチ機能を持ち、最大8個のGPU間でのデータのやり取りをさせることができる。
-
図7 XeHPCリンクはGPU間をコヒーレントに接続する高速リンクで、ロード/ストア、バルクデータ転送、同期転送などの機能を持つ。内蔵スイッチを使って最大8個のGPUをフルコネクトで接続できる

Xeリンクは図8に示すように、最大8個までのGPUを直結するネットワークを作ることができる。
-
図8 XeHPCリンクは8ポートを持ち、内蔵スイッチを使って最大8台のXeHPC GPUを完全接続できる

2スタックのノードを8個、Xeリンクで接続すると、FP32あるいはFP64で32,768×8演算/Clkのベクトル演算システムができる。マトリクス演算の場合は、TF32では262,144×8、BF16では524,288×8、INT8では1,048,576演算/Clkの演算ができるシステムとなる。
-
図9 2スタックのノードを8個、XeHPCリンクで接続すると、FP32あるいはFP64で32,768×8演算/Clkのベクトル演算システムができる。マトリクス演算の場合は、TF32では262,144×8、BF16では524,288×8、INT8では1,048,576演算/Clkの演算ができるシステムとなる

Ponte Vecchioは多数のタイルを3次元積層する複雑なGPUであり、パッケージテクノロジ、インタコネクト、電源供給、信号品質の確保など多くの新しい技術を開発して使用している。
-
図10 Ponte Vecchioの全体画像と新たに開発された技術。検証方法、ソフトウェアからIPアーキテクチャ、SoCアーキテクチャまで、11の新たな技術が使われている。スタックの写真の中の背中の黒いタイルはHBM2eメモリで、右上と左下の2個の金色の背中のタイルはXeリンクダイである。金色の2列に並んだ8個のダイがXeコア、これを囲むコの字型の8個の細長いダイがL1キャッシュやSLMと考えられる。そして、コの字の内側のうっすらと見えているのがRamboタイルと思われる

Ponte Vecchioは48個のアクティブ(配線だけでなくトランジスタを含む)タイルを使い、5種類の半導体テクノロジを利用している。Ponte Vecchio全体では100B以上のトランジスタが使われている。
-
図11 Ponte VecchioのSoC。Ponte Vecchioは47個のアクティブタイルで構成され100B以上のトランジスタのSoCである。タイルには5つのプロセスノードのダイが使われている。タイルは下から順に、EMIBタイル、Multi Tileパッケージ、Xeリンクタイル、HBMタイル、Baseタイル、Foveros、Ramboタイル、Computeタイルとなっている

Ponte Vecchioの開発では新しい技術の開発を必要とするものは多かったが、特に、全体の規模が巨大であること、多数のピンの接続を行うFoverosの開発、検証ツールと方法、信号品質と信頼度、電源供給などの実現がカギであったという。
-
図12 Ponte Vecchioの開発の鍵となるチャレンジ。全体の規模、Foverosの開発、検証ツールと方法、信号品質と信頼度、電源供給などの実現がカギであった

Ponte VecchioのComputeTileはTSMCのN5プロセスで作られており、Foverosのバンプのピッチも36μmと微細になっている。そして、1つのタイルに8個のXeコアを載せ、タイル当たり4MBのL1キャッシュを搭載している。
-
図13 Ponte Vecchioのコンピュートタイル。8個のXeコアと4MB/TileのL1キャッシュ。製造プロセスはTSMCのN5でFoverosのバンプピッチは36nmとなっている

Ponte VecchioのBase Tileは「Intel 7」プロセス(元の10nm Enhanced SuperFinプロセス)で作られるFoverosで、640mm2のサイズとなっている。Base Tileには144MBのL2キャッシュ、HBM2e 3D積層DRAMや高速のMDFIインタフェースなどが搭載されている。
-
図14 Ponte Vecchioのベースタイル。Intel 7プロセスで作られ、640mm2。144MBのL2キャッシュ、HBM2e、Host Interface、EMIBタイルを載せる

そして、Xeリンクを使って8個のPonte Vecchioを完全接続のトポロジで接続できる。TSMCのN7プロセスで作られ、リンクの速度は最大90Gbpsとなっている。
-
図15 Ponte VecchioのXe Linkタイル。8本のXeリンクと8ポートの内蔵スイッチ。製造プロセスはTSMCのN7でスイッチは90Gまで動作するSerdesを持つ

Ponte Vecchioの状況であるが、A0シリコンが完成し、FP32の演算で45TFlopsを超えるスループットが得られている。メモリファブリックのバンド幅は5TBpsを超える。チップ間接続のバンド幅は2TBpsを上回っている。そして、ResNet50での推論性能は43Kイメージ/秒、学習性能は3400イメージ/秒が得られているとのことである。
図16 Ponte VecchioのA0シリコンの現状。FP32の演算スループットは>45TFlops、メモリファブリックのバンド幅は>5TBps、チップ間接続のバンド幅は>2TBps、ResNet50での推論性能は43Kイメージ/秒、学習性能は3400イメージ/秒が得られている


一応、A0シリコンは動いているようであるが、5つの半導体プロセスのチップを組み合わせる複雑なチップであり、半導体の供給が不安定な最近の状況では47種のタイルを不足なく集めるだけでも大変そうである。なんとか大きな問題なく、アルゴンヌ国立研究所にPonte Veccio GPUを使うAuroraスパコンが納入されてもらいたいものである。