東芝と理化学研究所(理研)は8月20日、学習済みのAIを、できるだけ性能を落とさず、演算量が異なるさまざまなシステムに展開することを可能にする「スケーラブルAI」技術を開発したと発表した。
同成果は、東芝のAtsushi Yaguchi氏、東京大学大学院 情報理工学系研究科 数理情報学専攻の鈴木大慈准教授(理研 革新知能統合研究センター 深層学習理論チーム チームリーダー兼任)、東芝のShuhei Nitta氏、同・Yukinobu Sakata氏、同・Akiyuki Tanizawaの共同研究チームと、2017年4月から稼働を開始した理研AIP-東芝連携センターによるもの。詳細は、カナダ・モントリオールで現地時間8月27日まで開催中のAIに関する国際会議「IJCAI(International Joint Conference on Artificial Intelligence)2021」にて発表される予定だという。
AIは近年、さまざまな分野で活用されるようになってきたが、同じ機能のAIでも、活用するサービスやシステムが多岐にわたっている。そのため、それぞれの機器に搭載されるプロセッサの性能もさまざまで求められる要件も大きく異なってくるため、例えば「人物検出を行う」という機能1つとっても、同じAIを搭載することができない場合も多いことが分かっている。
-
開発の背景。同じ人物(の顔)検出でも、用途、使用するハードウェアなどにより、求められる要件が異なるため、深層ニューラルネットワーク(DNN)のサイズを適したものに変更する必要がある (出所:東芝Webサイト)

そのため現状では、人手で演算量と必要な精度とのバランスを試行錯誤しつつ、システムごとにAIを1から開発する必要がある。しかし、開発期間やコストがかかるとともに、利用するシステムごとに異なるAIが開発されるために管理が煩雑化してしまい、スケールメリットを出すことが難しい状況となっているという。
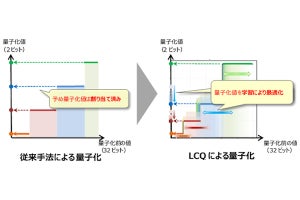
また、利用するシステムの演算能力に応じて単一のAIを展開するスケーラブルAIの開発が始まっているが、ベースとなるAIから演算量を落とすとAIの性能も落ちてしまうという課題を抱えている。そこで研究チームは今回、性能低下を抑えつつ演算量を調整することができるスケーラブルAI技術の開発を試みることにしたという。
具体的には、ベースとなるフルサイズの深層ニューラルネットワーク(フルサイズDNN)において、各層の重みを表す行列をなるべく誤差が出ないように近似した小さな行列に分解することで、演算量を削減したコンパクトDNNを用いる手法を採用。重要な情報が多い層の行列をできるだけ残しながら演算量を削減することで、近似による誤差を低減することを可能とすることを可能としたとする。
-
今回開発された技術の特徴。従来は、DNNのすべての層で行列の一部が一律に削除されていた。それに対して今回の技術は、層のうちの重要な部分では行列を残すなど、細かいチューニングが施されるイメージ (出所:東芝Webサイト)

学習中は、さまざまな演算量の大きさにしたコンパクトDNNとフルサイズDNNからのそれぞれの出力値と、正解との差が小さくなるようにフルサイズDNNの重みが更新されていくことで、あらゆる演算量の大きさでバランスよく学習する効果が期待できるとするほか、学習後は、フルサイズDNNを各適用先で求められる演算量の大きさに近似して展開することが可能となるという。
また、学習を通して演算量と性能の対応関係が可視化され、適用先に必要な演算性能を見積もることが可能となるため、適用先システムのプロセッサなどの選択が容易になるという点もメリットだと研究チームでは説明している。
世界的に知られている一般画像の公開データを用いて、被写体に応じてデータを分類するタスクの精度評価を行ったところ、今回の技術によって学習されたフルサイズDNNから演算量を1/2、1/3、1/4に削減した場合、分類性能の低下率はそれぞれ1.1%、2.1%、3.3%であり、従来技術よりも低下を抑制できることが確認されたという。
今回の成果を受けて研究チームでは、用途の異なる多様なシステムに向けたAI開発の効率化が期待できるとしており、今後は、今回の技術をハードウェアアーキテクチャに対して最適化することで、さまざまな組込機器やエッジデバイスへの適用を進め、実タスクでの有効性の検証を通し、2023年までの実用化を目指すとしている。
-
スケーラブルAIの効果。フルサイズDNNを一度開発してしまえば、あとは要件やハードウェアの仕様などに合わせてDNNのサイズを調節するだけで、開発に要する費用と時間を削減することができる (出所:東芝Webサイト)