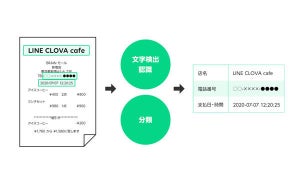
LINEは11月25日、NAVERと共同で日本語に特化した超巨大言語モデル開発(膨大なデータから生成された汎用言語モデル)と、その処理に必要なインフラ構築についての取り組みを開始すると発表した。超巨大言語モデルは、AIによる、より自然な言語処理・言語表現を可能にするもので、LINEによると、日本語に特化した超巨大言語モデル開発は、世界でも初めての試みだという。
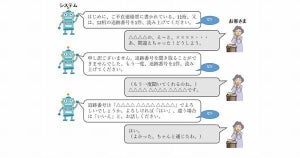
従来の言語モデル(特化型言語モデル)では、Q&Aや対話などの各ユースケースに対して、自然言語処理エンジニアが個別に学習する必要があった。一方、汎用言語モデルでは、新聞記事や百科事典、小説、コーディングなどといった膨大な言語データを学習させた言語モデルを構築し、その上でコンテキスト設定を行うためのFew-Shot learning(ブログの書き出しや、プログラミングコードの一部などを与えること)を実行するだけで、さまざまな言語処理(対話、翻訳、入力補完、文書生成、プログラミングコードなど)を実行することが可能となり、個々のユースケースをスムーズに実現できるとしている。
両社は今回、日本語に特化した汎用言語モデルを開発するにあたり、1750億以上のパラメーターと、100億ページ以上の日本語データを学習データとして利用する予定だ。これは現在世界に存在する日本語をベースにした言語モデルのパラメーター量と学習量を大きく超えるものだといい、パラメーター量と学習量については、今後も拡大させていく。
また、同モデルを迅速かつ安全に処理できるという700ペタフロップス以上の性能を備えたスーパーコンピュータを活用し、超巨大言語モデルの土台となるインフラの整備を年内に実現する予定。開発された超巨大言語モデルについては、新しい対話AIの開発や検索サービスの品質向上などLINEの各種サービスへの活用のほか、第三者との共同開発や、APIの外部提供についても検討する方針だ。