NTTデータは7月10日、金融版のBERT(Bidirectional Encoder Representations from Transformers:Googleの自然言語処理モデルで自然言語処理分野のさまざまなベンチマークにおいて従来モデルの精度を上回るなど注目されている)を用いた自然言語処理技術に関して、銀行や証券会社などの金融関連企業を募り、7月以降に順次、実証検証を開始すると発表した。
金融版BERTとは、BERTを金融業界向けにNTTデータが独自に特化させた言語モデル。金融専門用語や特有の文脈を含む文書を解析する際に都度言語モデルの学習を行う必要がなくなり、学習工程を短縮しつつ、高精度の結果を得ることを可能としている。
-
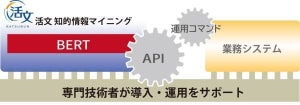
金融版BERTイメージ

BERTには、これまでの自然言語処理技術では難しかった文脈を踏まえた解析が可能という特徴があり、言語モデルの適用で金融業界コールセンターにおけるFAQ回答引き当てや、営業日報からの情報抽出など、自然言語処理技術を要するさまざまな処理の精度向上が期待できるという。
近年、自然言語処理技術のビジネス活用に向けた研究が進み、金融業界においてもチャットボットによる顧客対応高度化や審査支援による業務効率化などに活用されつつある一方で、金融業界の文章は業界特有の専門性の高い用語や言い回しが多く、辞書整備や多数のルール構築が必要になるなど、自然言語処理技術の適用のためには労力と時間を要していた。
また、日本語金融文書へのBERT適用には、まず日本語向けのBERTモデルが必要となるが、大規模なコーパス(テキストや発話を大規模に集めてデータベース化した言語資料)で学習させた日本語モデルは少ないなどの課題もあったという。
このような課題に対し、同社では大規模コーパスで学習させたNTT版BERTをもとに、独自に収集した金融関連文書を用いて金融版BERTを開発し、ビジネス適用の実証検証を開始することにした。
Googleの発表したBERTモデルは13GB以上のコーパスで学習させている一方、公開されている日本語向けBERTモデルの大半が日本語Wikipediaコーパス(3GB程)で学習させたものだったという。NTTメディアインテリジェンス研究所では、日本語Wikipediaに加え、ニュースサイトやブログから収集した大規模コーパス(12.7GB)を用いており、日本最大規模のコーパスで学習させたBERTモデル(NTT版BERT)を開発。
金融版BERTは、NTT版BERTにNTTデータで独自に収集した金融関連文書を用い、金融文書向けに追加学習したモデルとなり、特定分野のコーパスで学習させたBERTモデルは、その分野のタスクにおいては一般的なコーパスで学習させたBERTモデルより高い精度を達成するという結果が報告されているという。
金融文書への自然言語処理における金融版BERTモデル性能を評価するため「金融文書における単語予測の正確性評価」「金融系資格試験における得点比較」の2つの事前検証を実施した。金融文書における単語予測の正確性評価は、同社が収集した金融関連文書に対して単語マスキングを行い元の単語予測精度を評価。
金融系資格試験における得点比較では、金融知識を求められる課題として教材制作会社作成の一種外務員資格試験の模擬試験に回答するBERTを活用した試験回答AIを開発し、各モデルによる得点を比較した。いずれの検証においても、NTT版BERTが大規模学習の効果を発揮していること、さらに金融版BERTは金融文書向けに適したモデルになっていることが確認できたという。
金融版BERTの活用業務としては、日報からの情報抽出、稟議書の記載内容チェック、財務情報からのリスク抽出、FAQの回答自動引き当て、チャットボットによる問い合わせ対応などを想定している。
今後、同社は2020年度中に金融版BERTの実証検証5件の実施を予定しているほか、実証検証での成果を活用して2021年度に金融版BERTサービス提供開始を目指す。
なお、同社の持つ自然言語処理に関する独自ノウハウや技術を活用し、金融版BERTモデルの実ビジネス適用を進めていくため、検証賛同企業を募集しており、2020年9月末まで金融機関の申し込みを受け付ける。受付後に金融機関とNTTデータで検証計画を擦り合わせ、同社で効果測定・分析を行い、検証を通じて技術の有効性やビジネスへの導入に向けた課題・対応方法を明らかにするという。