東京エレクトロン デバイス(TED)は12月12日、予知保全を実現するという異常判別プログラム自動生成マシンである「CX-M」に原因分析を可能にする「マルチカラム(データ合成なし)モデル生成機能」を追加し、「CX-M ver5.0」として提供開始した。
-
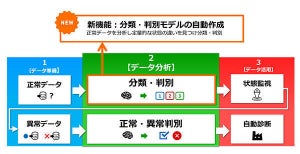
判別モデルの判断基準の可視化

予知保全では、装置の稼働データや、振動、センサーなどの複数の時系列データカラムを分析し、特徴をとらえて判別モデルを生成する。
従来の同製品は、複数の時系列データカラムを合成してからデータ分析し判別モデルを生成していたため、判別モデルの判断基準や、判別モデルによる判定理由の明確化(定量化、可視化)が困難だったという。
このため、発生事象の原因分析ができず、ユーザーの利用方法は判別モデルの判定結果を用いた予知保全に留まっていたという。
新バージョンでは、複数の時系列データカラムを合成せずに判別モデルを生成する「マルチカラム(データ合成なし)モデル生成機能」により、判別モデルの判断基準に各データカラムがどの程度影響するかを定量的に示すことが可能になり、判別モデルによる判定理由の可視化を実現したとのこと。
ユーザーは、判定根拠となったデータカラムをたどって発生事象の原因を分析することで、判別に影響を及ぼす要因に対して製造現場で具体的な対策を講じられるようになるという。
-
判別モデルで判定した理由の可視化

-
判定根拠から正常・異常オリジナルデータのグラフ比較

同バージョンでは、判別モデルの判断基準の可視化として、判別モデルの特徴(判断基準となるデータカラムと位置)を定量表示できる。
また、判別モデルで判定した理由の可視化として判定根拠となるデータ上の特徴(データカラム・位置・自信度)を定量表示可能であり、判定根拠からの正常・異常オリジナルデータのグラフ比較により発生事象の原因を具体的な情報から推定し現場での対策を検討できるとのこと。
なお同社は購入を検討するユーザー企業に対して同製品によるデータ分析診断を提供しており、ユーザー企業のデータを利用した場合の分析結果を確認した上で購入を検討できるとしている。