NECは8月5日、多種多様なデータの本質的な意味をAIで推定する「データ意味理解技術」を開発したと発表した。新技術は従来、専門家が時間をかけて行っていた分野や業種の異なる複数の表データの統合作業を、高速かつ高品質に自動化するものだという。
近年、データ流通基盤や情報銀行など、データを部門間、企業間、さらには業界間で共有し統合することで、これまでにない横断的な分析を行う取り組みが活発になっているが、保有者の異なるデータを横断的に分析するには、表名や列名が統一されていない多様なデータを結合することが必要となる。
これまで、作業者、企業、業界ごとの違いから表名/列名には大きな表記揺れが存在するため、データ管理の専門家が膨大な量の表データを精査し、何のための表データか、その表データの各行や列が何を表しているかを見極め、人手で統合を行っていたという。その結果、データ統合に膨大な時間がかかり、分析がすぐに開始できない、担当者ごとのスキルにばらつきが出て分析精度が悪化するなどの問題が顕在化していたと同社は指摘する。
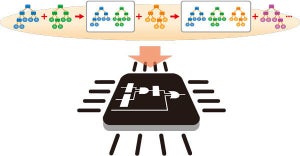
新技術は、多種多様なデータの統合を専門家と同等の品質、かつ短期間で再現し、データ統合に関する業務効率の向上を可能にする、NEC独自の機械学習アルゴリズム。具体的には、表データの構造と数値特性を含む、さまざまな単語のナレッジグラフ(さまざまな単語の意味をネットワークで表現したデータベース)を活用した独自の機械学習技術となり、同社のAI技術群「NEC the WISE」の1つとなる。
-
従来技術と新技術との比較

新技術の特徴して「データ分布の傾向をとらえる特徴量に基づき、ナレッジグラフとの紐づけを実現」「ナレッジグラフ上での意味の共起関係を活用し、高精度な意味推定を実現」の2点を挙げている。
ナレッジグラフとの紐付けに関しては、元々付与されている表名や列名を手がかりとするのではなく、各データ列の数値分布の統計的な傾向を手がかりとするため、事前にナレッジグラフ内の各単語について、その単語と共起する数値を収集し、単語の数値分布を含む独自のナレッジグラフを構築する。
同じ意味を持つ数値データは統計的な分布傾向が類似することから、数値データ列から数値の出現頻度の分布傾向を示す特徴量を算出し、ナレッジグラフ上の単語毎の数値分布と比較することで、例えば列名のないデータについても「売上高」といった意味の推定を可能としている。
-
ナレッジグラフとの紐付けの概要

また、高精度な意味推定については、表データにおける数値データ列では例えば「29、24、23」など、それ単独では「年齢」や「気温」など、さまざまな意味が当てはまるため、文字データ列と比べて正しい意味の推定はより困難となることから、「推定対象のデータ列の意味候補」と「同一表データにある他のデータ列の意味」の共起関係をナレッジグラフ上のネットワーク距離(=データの意味間の共起関係の強度)を活用し推定することで、高い精度での推定を実現するという。
例えばあるデータ列について、同じ表データに「氏名」の項目が含まれていれば、ナレッジグラフから、「気温」データではなく、より関係性の強い「年齢」データであることを推定するとしている。
-
高精度な意味推定の概要

今後、同社は新技術をサプライチェーンに加え、データレイクといわれるさまざまな分野の形式の異なるデータが集まるデータベースや、データを一元管理するデータマネジメント基盤(DMP)、情報銀行、データ流通プラットフォームなど、情報共有基盤への汎用的な活用を目指し、研究開発を進めていく方針だ。