ルネサス エレクトロニクスは6月13日、次世代の組み込みAI(e-AI)の実現に向けた基礎技術として、メモリデータの読み出し中に積和演算まで可能なSRAMベースのProcessing-in-Memory(PIM)アーキテクチャを開発。これを活用したConvolutional Neural Network(CNN)処理を実現するAIアクセラレータを搭載したテストチップにおいて、8.8TOPS/Wの電力効率を実証したと発表した。
-
テストチップ(中央の一番大きいチップ)を搭載したテストボード。ダイサイズは3mm×3mmだが、ピン数の関係から、パッケージはやや大きめのものとなっている

同成果は、同社インダストリアルソリューション事業本部 事業計画統括部 e-AI事業推進室 主任技師の奥村俊介氏らによるもの。詳細は2019年6月9日から14日まで京都で開催されている「2019 VLSI技術/回路シンポジウム(2019 Symposia on VLSI Technology and Circuits)」にて発表された。
半導体のプロセス微細化による性能向上の限界が近づきつつある近年、プロセスの微細化以外のアーキテクチャによる大規模化が進む計算機における消費電力の低減が求められている。Near Data Processingとも呼ばれるPIMは、データをできる限り同じロジック内で演算をすることで、データを移動させる際に必要となる電力を削減し、低消費電力化を図ろうという考え。1回あたりのデータ移動に必要な消費電力そのものはそこまで大きくないが、頻繁にデータのやり取りが生じ、かつその量が膨大に及ぶ演算では、そのトータルの消費電力は意外と馬鹿にできないほどのものとなる。
特に世界トップクラスの演算性能を有するスーパーコンピュータ(スパコン)などは10MWを超す消費電力がざらであり、環境負荷などの側面からも性能を向上させつつ、消費電力はできる限り抑えることが求められている。また、近年注目を集めている人工知能(AI)も、学習はGPUを搭載したスパコンやHPCを活用するが、それを実際のアプリケーションに搭載して推論処理を活用する場合、クラウド経由でそうした大規模システムに接続するのではなく、手元のデバイスで行おうと思えば、バッテリーの消費なども考慮し、できる限り低消費電力な半導体でそれを行うことが求められることとなる。
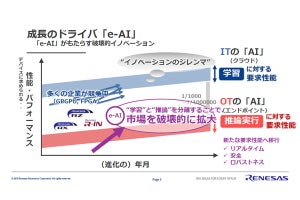
同社が今回開発した技術をe-AI向けとして位置づけるのも、同社がエッジやOT(Operation Technology)分野での推論活用にフォーカスしているため。今回開発の技術は第4世代(クラス4)として電力対性能10TOPS/Wを実現するための要素技術の1つとしている(同社の指すクラスは、独自指標で、クラス1が10GOPS/W、クラス2が100GOPS/W、クラス3が1TOPS/W、クラス4が10TOPS/Wと、世代ごとに1桁ずつ電力対性能比が向上していくものとなっている)。
e-AIが目指す中心分野はOT。e-AIの演算性能はクラスで分けられており、クラスが1つ上がるごとに演算性能も1桁あがっていくイメージとなっている。現在、すでにクラス2の製品までは展開済みで、今後、クラス3の実現に向けた研究開発が継続して進められている。今回発表の技術は、さらにその先の10TOPS/W級の電力性能を実現することを目指した要素技術の1つという位置づけになっている (資料提供:ルネサス)


3値のSRAM構造を考案
今回のSRAMベースのPIMアーキテクチャの最大のポイントは、一般的な2値のSRAMではなく、3値(-1,0,+1)のSRAM構造を採用したこと。これにより、ニューラルネットワークの重みデータを1ビットではなく、任意のビット数に拡張することを容易にした。
-
従来の2値だと多ビットの表現ができなかったが、3値にすることで、ビット数をスケーラブルに設定することが可能となった。今後、実用化にあたっては、同社のe-AI対応マイコンやSoCのSRAM領域は3値の方式が採用されていく見通しだという (資料提供:ルネサス)

また、メモリのデータは、ビット線電流の値を検出することで読み出しが行われるが、従来手法であるA/Dコンバータ(ADC)では、回路規模が大きくかつ消費電力も大きかったことから、コンパレータ(1ビットセンスアンプ)を用いて、検出したい電流値と逆の電流を生成することで電流値を自由に制御できるレプリカセルとの差分を時系列に読み出すことで、高精度なメモリデータの読み出しを可能にする回路を実現。さらに、積和演算の結果が0の状態の場合、比較器を停止させることで、さらなる電力消費の抑制も実現。既存のADCベースのPIMアーキテクチャに比べて、最大で1/2~1/6ほどの電力削減効果を得られることを確認したとする。
1ビットセンスアンプを用いて、電流量を高精度に読み出すことを可能にしたほか、演算結果が0の場合は1ビットセンスアンプの動作を停止する機能を開発することで消費電力の低減を可能とした (資料提供:ルネサス)


このほか微細なプロセスで問題になってくるのが、SRAMのバラつき。もし、バラつきが大きいメモリセルに+1や-1の情報や重みデータが格納されてしまうと、出力される電流値が変ってしまい、演算の誤差が大きくなってしまう可能性があったことから、メモリセルごとのバラつきを把握し、バラつきの大きいセルには基本的に0を配置、+1や-1のような活性化ニューロンについては、バラつきの大きなセルが選択された場合、バラつきの小さいセルに選択的に入れ替えをできるようにしたことで、通常のメモリセルのような冗長用セルを用意しなくても、高品質な演算を可能とした。
-
製造プロセスのバラつきはプロセスの微細化が進めば進むほど問題になる課題であり、根本的に避けられない。それを逆手にとって、バラつきの大きいセルに+1や-1の入力がある場合は、自動的に隣接するバラつきの小さいセルに配置されるようにすることで、余分なメモリセルを用意せずに、メモリ領域を有効に活用することができるようにした (資料提供:ルネサス)

テストチップにて認識率99%以上を確認
実際に同社が12nmプロセスをベースにして開発した3mm×3mm角のテストチップを用いた実験では、4クラスタにエリア分けが行われ、1クラスタごとに通常のSRAM領域、PIM領域、ロジック領域を用意。1クラスタごとのCNN総数は最大32層(4クラスタ合計で128層)で、PIM容量は1.185Mビット(同4.74Mビット)、SRAM容量は3.145Mビット(同12.58Mビット)となっており、各クラスタごとに別々のAI処理を実行したり、1つにまとめてAI処理を実行したりといったことが可能な構成になっている。
-
開発されたテストチップの概要。4クラスタ構成で、1クラスタごとにメモリ内での演算処理が可能な作りになっている (資料提供:ルネサス)

同チップを用いた手書き文字認識(MNIST)では99%以上の認識率を低消費電力で実現できることも確認したとする。
-
テストチップを用いた手書き文字認識の実験結果 (資料提供:ルネサス)

実際に、学会の開催に先んじて披露されたデモではテストチップ搭載基板はボタン電池1個で動作する様子が示されており、高速なAI処理を低消費電力で実行可能な様子が示された。
手書き文字認識および人体検出のデモの様子。デモボードはボタン電池1個で動作可能なほど低消費電力。デモ構成はGR-Peachをベースに、LCDシールドとカメラシールド、カメラシールドとGR-Peachの間にテストボードが挟まれているという構成




実用化の目標は2022年以降の製品への搭載
同社は、今回の技術をあくまでe-AIのクラス4(目標10TOPS/W)を実現するための要素技術の1つという位置づけとしており、同技術だけでそれが実現できるわけではなく、先行して開発が進められているDRP(Dynamically Reconfigurable Processor)の進化版などと組み合わせていく必要があるとしている。
また、バラつきを把握し、データが入るメモリセルの位置を変更できる技術はできたものの、それを実際にどうやってバラつきが生じているのか、といったことを把握する技術は今後、開発が待たれるものとなるとしており、こうした背景から、実際に同技術が同社の製品に採用されるとしても2022年以降の製品での搭載を目指すロードマップであるとする。
なお、同社はフラッシュ混載マイコン技術などの開発も進めているほか、近年はFRAMやMRAMを搭載したマイコンなども他社から登場しているが、今回開発したPIMアーキテクチャは、3値構成が可能であれば、SRAMに限らず、そうしたさまざまなメモリに転用できるものであり、将来的にはそうしたSRAM以外のメモリでの活用も期待できるようになるとしている。