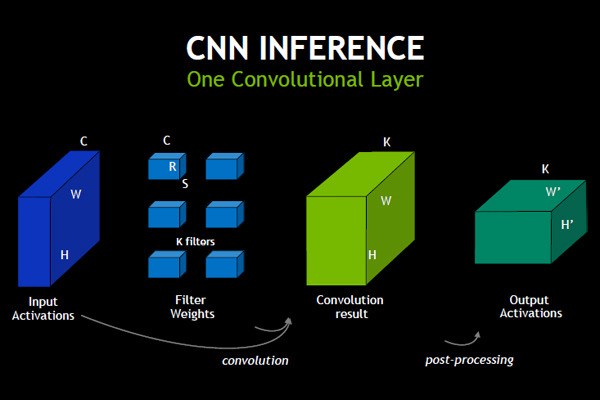
COOL Chips 22の最初の基調講演は、NVIDIAのGPUエバンジェリストの馬路徹氏による「GPU: A true AI Cool-Chip with High Performance/Power Efficiency and Full-Programmability」と題する講演であった。
-
COOL Chips 22で最初の基調講演を行うNVIDIAのGPUエバンジェリストの馬路徹氏

CPUクロックの向上による高性能化は止まったが、まだ、ムーアの法則による微細化は続いており、GPUはトランジスタ数の増加の恩恵を受けてきた。次の図は2001年からのNVIDIAのGPUのコア数の増加を示すものであり、2001年のGeForce 3は1~4コアであったものが、2017年のVolta GPUではFP32のコア数は5120、FP64のコア数は2560になっている。
-
NVIDIAのGPUのコア数の増加の歴史。2001年のGeForce 3は1-4コアであったが、2017年のVoltaではFP32コアが5120個、FP64コアが2560個に増加している (このレポートのすべての図はCOOL Chips 22における馬路氏の基調講演の発表スライドのコピーである)

シングルスレッドのCPUの性能は、かつては年率1.5倍で向上していたが、現在では年率1.1倍に鈍化している。しかし、GPUの性能はムーアの法則が飽和してきた現在でも年率1.5倍で増加しており、GPUはアクセラレータとして必須になってきている。
と述べられたが、これは誤解を招く表現で、GPUの性能が上がっている大きな理由は、多数のコアで多数のスレッドを並列に実行しているからであり、CPUでもコア数を増やせばGPUと同様にスループット性能は向上するはずである。
しかし、CPUでそれをやらないのは使い方が違うからであり、GPUが特別な性能向上法をもっているというわけではない。ただし、GPUの性能向上は大きく、必須のアクセラレータになってきているという指摘は正しい。
-
CPUの性能向上は年率1.1倍程度に鈍化しているが、GPUは年率1.5倍の性能向上を続けている。このため、GPUはアクセラレータとして必須になってきている

オークリッジ国立研究所のSummitスパコンは、約4万個のVolta GPUを使い、HPCでは143PFlopsのHPL計算性能を達成し、AIでは3PFlopsの性能を持つ、世界一のスパコンである。そして、Top500の上位10システムの内、5システムがNVIDIAのGPUを使っているという状況になっている。
-
Top500 1位のSummitはNVIDIAのVolta GPUを約4万個使い、HPLで143PFlopsの性能を達成し、AIでは3PFlopsの性能を持つ

CPUは、1つの仕事を出来るだけ早く実行する設計になっており、キャッシュの階層も深くキャッシュミスを減らす設計になっている。このため、単精度の浮動小数点演算を1回行うのに126pJのエネルギーを必要とする。一方、GPUは多数のスレッドを並列に実行してスループットを高める設計であり、回路的にも遅いクロックでエネルギー効率が高い造りになっている。また、ローカルメモリやキャッシュもそれに適した作りになっている。このため、単精度の浮動小数点演算1回当たりのエネルギーは28pJとエネルギー効率はCPUの約5倍である。
-
左はIntelのBroadwell E5 CPUのチップ写真、右はNVIDIAのPascal P100 GPUのチップ写真である。CPUはレイテンシを最適化する設計であり単精度の演算に126pJのエネルギーを必要とする。GPUはスループットを最適化する設計であり、28pJで単精度演算を行うことができる

AI/Deep Learningの発展は目覚ましく、画像認識、音声認識、言語間の翻訳、推奨などいろいろな方面に使われている。そして、次の図に示すように、Convolution Network、Recurrent Network、Generative Adversarial Network、Reinforcement Learningなど用途に応じていろいろなネットワークが作られている。このため、AI/Deep Learning用のLSIは固定機能ではだめで、プログラマブルでなければならない。
-
ディープラーニングと言っても用途に応じて色々なネットワークが作られており、これらすべてに対応するためにはプログラマブルなアクセラレータでなければならない

また、会話型のAIサーチを行うには、オーディオのノイズ除去を行い、スピーチ認識して、言語モデルを使ってから、質問の理解を行わせる。ビジュアル入力はJPEGデコードして、リサイズし、対象認識してから、理解させる。そしてAIからのリコメンデーションをテキストtoスピーチでスピーチに変換し、ボイスエンコーダで音声に替える。画面情報は自動的にページレイアウトを行って見やすいように提示する。このように多くのインテリジェントな処理が必要になり、やはりプログラマブルなシステムであることが重要になる。
-
会話型のAIサーチを行うには、オーディオのノイズ除去、スピーチの解析、質問の理解など、多くのAI処理が必要になる。このため、プログラムで処理を変えられるシステムであることが必須である

そして、それぞれのAIネットワークの複雑さも増加している。イメージ認識のInception v4ネットワークのGOPS×バンド幅は2012年のAlexNetの350倍のサイズであり、音声認識のDeep Speech 3は2014年のDeep Speechの30倍、翻訳のMoEは2015年のOpenMNTの10倍となっている。このようにより複雑なネットワークの計算を行うためには、より高性能のアクセラレータが必要になる。
-
この図はイメージ認識、スピーチ認識、翻訳のネットワークのGOPS×バンド幅の増加を示すものである。イメージ認識は4年で350倍、スピーチ認識は3年で30倍、翻訳は2年で10倍複雑になってきている。このため、最適化とアクセラレータの高速化が必要になっている

GPUを使った学習のスピードは、GPUハードウェアの能力の向上とcuDNNなどのソフトウェアの最適化で、2013年のK40と比べると2016年のP100+cuDNN 5では60倍に改善している。
-
GPUによる学習の速度は、ハードウェアの性能向上とcuDNNなどのソフトウェアの最適化で、2013年のK40から2016年のP100+cuDNN5で60倍に性能が向上している

そして2017年のVoltaではTensorコアの追加で、半精度のFP16での計算であるが、120TFlopsと12倍の性能になっている。
-
そして2017年には、Tensorコアの搭載で、さらにディープラーニング演算性能が12倍に向上した

さらに2018年のTuring GPUではINT8、INT4をサポートし、演算精度が低くて良い場合には、さらに高速の演算ができるようになった。
-
2018年のTuring GPUではINT8とINT4でのテンソル乗算をサポートし、INT8、INT4の精度の演算で良い推論処理の性能を改善している

その結果、TuringアーキテクチャのTesla T4 GPUでは、DeepSpeach 2ではCPUの21倍、ResNet-50ではCPUの27倍の推論性能が得られるようになっている。
-
Tesla T4では低精度のINT8、INT4演算のサポートで、スピーチ認識ではCPUの21倍、ビデオ画像の認識ではCPUの27倍の性能となった

最新のTuring GPUでは、SMの演算は14TFlopsで、これと並列に整数演算もできるようになっている。そして、TensorコアではFP16で114TFlops、INT8では228TOPS、INT4では455TOPSの演算ができる。
また、TuringはRTコアというレイトレーシング用のアクセラレータを持っており、10GigaRay/sで光線と物体表面の交点を求めることができる。
なお、この図はアーティストがCGで描いたものであり、実際のチップ写真ではなく、学術的な意味はない単なる壁紙である。
-
Turing T4 GPUの諸元。コアのFP32演算は14TFlops、TensorコアはFP16で114TFlopsの性能を持つ。低精度の演算をサポートしており、INT8で228TOPS、INT4で455TOPSの演算ができる。絵はチップ写真ではなく偽物である