ソニーは11月13日、ディープラーニング(深層学習)の開発用フレームワーク「コアライブラリ:Neural Network Libraries」と産業技術総合研究所(産総研)が構築・運用する世界最大規模のAI処理向け計算インフラストラクチャ「AI橋渡しクラウド(ABCI)」を活用し、ディープラーニングの学習速度において世界最高速を達成したと発表した。
ディープラーニングは、人間の脳を模倣したニューラルネットワークを用いた機械学習の一手法であり、ディープラーニングを使用することで画像認識や音声認識の性能が向上している一方で、認識精度を向上させるために学習データのサイズやモデルのパラメータ数が増加しており、これに伴い計算時間が増加し、一度の学習に数週間から数カ月を要する場合もあったという。
AI開発においては、さまざまな試行錯誤を繰り返す必要があるため、学習時間を短縮させることは重要となることから、複数のGPUを活用した分散学習による学習時間の短縮が注目されている。
分散学習は、GPU数が増加すると一度のデータ処理個数であるバッチサイズの増加に伴い学習が進まないケースや、GPU間のデータ送受信の処理遅延により学習速度が低下するケースがあるという。
同社では、学習の進行状況に応じて最適なバッチサイズや利用GPU数を調整する技術を用いることでABCIのような大規模なGPU環境でも学習を可能としたことに加え、ABCIのシステム構成に適したデータ同期技術によりGPU間の通信を高速化した。
これらの技術をNeural Network Librariesに実装し、産総研「ABCIグランドチャレンジ」プログラムより提供を受けたABCIの計算リソースを用いて学習を実施した。
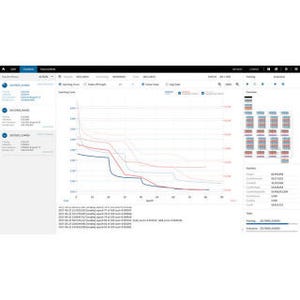
結果として、ディープラーニングの分散学習速度を計る際に業界で一般的にベンチマークとして活用されているImageNet/ ResNet-50(それぞれ一般的に利用されている画像認識用データセットおよび画像認識用モデル。ImageNetデータセットを利用してResNet-50モデルの学習を実施)の学習を約3.7分(最大2176基のGPU利用時)で完了させ、現状の世界最高速を達成したという。
なお、今回の研究成果は「ImageNet/ResNet-50 Training in 224 Seconds(PDF)」で公開している。
今回の研究成果は、Neural Network Librariesによる学習・実行が世界最速クラスのスピードで実行できることを実証しており、同フレームワークを用いることで、短い試行錯誤時間でディープラーニングを用いた技術開発ができるようになることを示したという。