京都大学(京大)は、動物の行動データから報酬に基づく行動戦略を明らかにする機械学習法を考案し、これを線虫の行動へと応用することでその有効性を示したと発表した。
同成果は、京大生命科学研究科の本田直樹 准教授、情報学研究科の山口正一朗 氏、石井信 教授と、名古屋大学の森郁恵 教授らとの共同研究グループによるもの。詳細は米国の学術誌「PLoS Computational Biology」に掲載された。
動物は多くの報酬を得るため、状況に応じた 「行動戦略」を持って生きていることが知られている。報酬には食べ物や金などの実態を伴ったものだけでなく、間接的にそれらに結びつくものも含まれているため、自由に行動している動物を観察しているだけでは「動物が何を報酬として意思決定を行い、行動しているのか?」を知ることは困難だった。
研究グループは今回、動物の行動データから報酬に基づく行動戦略を明らかにする機械学習法(逆強化学習法)を考察。この手法は一般的に知られる強化学習の逆問題を解くというものだ。
-
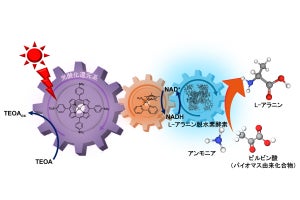
今回の研究の概要図 (出所:京都大学Webサイト)

強化学習は、どの状況でどれくらい報酬を得られるのかはあらかじめ決められており、試行錯誤によって得られる報酬を最適化する行動戦略を見つけ出すことが目的とするもの。一方の逆強化学習では、動物はすでに最適な行動戦略を獲得しているとして、計測された行動時系列データから未知の報酬を推定することが目的になる。
同グループは逆強化学習法の応用先として、モデル動物である線虫C. elegansの温度走性行動に注目した。通常、一定の温度で餌を成育した線虫はその成育温度を記憶し、温度勾配下では成育温度を目指して移動し、逆に一定の温度で餌のない飢餓状態で成育した線虫は、温度勾配下で成育温度から逃げて遠ざかることが知られていた。
しかし、線虫がどのような戦略にしたがって行動しているのかはこれまで謎だった。そこで同グループは、線虫を温度勾配においてトラッキングすることで、行動時系列データを取得し、逆強化学習法により、線虫にとって何が報酬となっているのかを推定した。
その結果、餌が十分ある状態で育った線虫は、絶対温度および温度の時間微分に応じて報酬を感じていることが判明。さらに、この報酬に基づく戦略は2つの異なるモードから構成されていたことも分かった。1つは効率的に成育温度に向かうモード、もう1つは同じ温度の等温線に沿って移動するモードを表していた。
また飢餓状態で育った線虫は絶対温度のみに依存した報酬により、成育温度を避ける戦略を持っていることが明らかとなった。さらに、推定された報酬を用いて、線虫行動をコンピュータでシミュレーションしたところ、線虫の温度走性行動が再現され、逆強化学習法の妥当性が示されたという。
今回の成果を受けて研究グループは、逆強化学習法を用いることで、従来の行動が制限された行動実験系から開放され、より自然な状況において自由に振る舞う動物の行動戦略の研究が進むことが期待されるとしている。