




|
SAPジャパン バイスプレジデント プラットフォーム事業本部長 鈴木正敏氏 |
SAPジャパンは11月7日、ビッグデータ活用のための新ソリューション「SAP Data Hub」の提供開始を発表した。
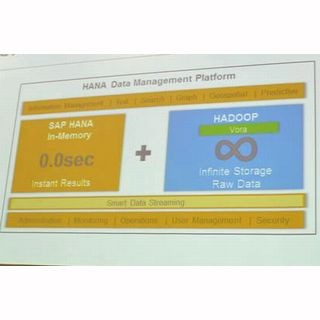
バイスプレジデント プラットフォーム事業本部長の鈴木正敏氏は、「SAP Data Hub」について、エンタープライズデータの高速処理を行う「SAP HANA」とビッグデータの高速処理を行う「SAP Vora」によるインメモリ・プラットフォームを強化する製品と説明した。エンタープライズデータとは、SoR(System of Record)と呼ばれる基幹システムのデータだ。
鈴木氏は、「SAP Data Hub」の主な特徴として、「モダンな画面でビッグデータのランドスケープの管理を実現」「データ駆動型アプリケーションをアジャイル開発」「ビッグデータとエンタープライズデータへの統合アクセス」の3点を挙げた。

|

|
「SAP Data Hub」の主な特徴 |
「SAP Data Hub」はこれらの機能により、ビッグデータ活用における課題を解決していくという。その課題とは「データガバナンスの欠如」「新たな開発手法による実装の難しさ」「ビッグデータとエンタープライズデータの分断」の3点である。
「現在、ビッグデータはどこで生成され、どのように加工されたのかが不明な状況が多々あり、データの信頼性が確立していない。また、生のデータを活用できるデータにするためのプロセスが煩雑であるがゆえに長期化している」(鈴木氏)

|
SAPジャパン プラットフォーム事業部 SAP HANA CoE シニアディレクター 椛田后一氏 |
続いて、プラットフォーム事業部 SAP HANA CoE シニアディレクターの椛田后一氏が、「SAP Data Hub」の詳細を説明した。同氏は、鈴木氏の話を引き継いで、「SAP Data Hub」がどのようにしてビッグデータ活用における課題を解決するのかを紹介した。
「データガバナンスの欠如」については、データソースの管理に加え、データの生成/加工の工程をトレースする機能を提供することで、データの信頼性を高める。
「新たな開発手法による実装の難しさ」については、組織全体に広がるさまざまなソースからの情報にアクセスして、それらを組み合わせたり、変換したり、処理したりする強力なデータパイプラインを作成できる設計環境を提供する。また、高機能ライブラリを利用して、コンピューター処理やTensorFlowなどの機械学習機能をパイプラインに組み込むことができる。
「ビッグデータとエンタープライズデータの分断」については、「SAP HANA」と「SAP Vora」の連携機能を活用して各システムでデータを共有することで、ビッグデータとエンタープライズデータの統合アクセスを実現する。

|
GUIベースの統合Cookpitで、複数のランドスケープを管理できる |
ちなみに、SAPの本社は10月12日、「SAP Vora」の新版を発表している。新版では、GoogleのKubernetesとDockerコンテナが統合されており、パブリッククラウドにおけるデプロイメントとクラスタ管理がシンプルになっている。
また、データソースとして、Amazon S3のサポートを開始、Azure Data Lakeについても対応を予定しているという。

|
「SAP Vora」の新版の強化点 |












![[SAPPHIRE NOW 2017]SAP、IoTや機械学習のツールセット「SAP Leonardo」を正式発表](/techplus/article/20170519-sap_sapphire/index_images/index.jpg/iapp)