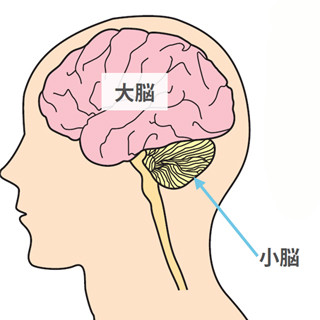
SC16において、IBM ResearchのJun Sawada氏が、神経系を模した情報処理を行う「TrueNorth」について発表を行った。
|
|
|
TrueNorthについて発表するIBM Researchの沢田氏 |
TrueNorthは、入力をあちこちに接続するAxon相当の機能と複数の入力を総合して出力を出すNeuron相当の機能からなり、入力と出力の接続は左の図のようにバリエーションがある。TrueNorthでは、これを右側の図のように入力を横方向の線、出力回路への入力を縦方向の線とする格子を作る。格子の交点に黒丸がついているところは、入力が出力に伝えられることを示している。どの交点を接続するかで、接続のバリエーションを作り出している。
接続されている交点では、各入力の値にそれぞれの重みを掛けて、縦線全体の合計を求める必要があり、単純な配線の接続ではない。

|
|
入力回路の信号を伝える横線と入力を総合して出力回路に伝える縦線が格子状に配置され、各交点が信号を伝えるかどうか、入力を総合するときに、各入力値に掛ける重みをプログラムすることができる (このレポートのすべての図は、SC16における沢田氏の発表スライドを撮影したものである) |
TrueNorthチップは、1M個のニューロンと256M個のシナプス(格子の交点の数)を集積したチップで、28nm CMOSプロセスを使い、54億トランジスタを4.3cm2のチップに集積している。神経と同様にパルス信号を伝達する回路を使っており、チップの消費電力は70~200mWと小さい。

|
|
TrueNorthチップは1Mニューロンと256Mシナプスを集積する。28nm CMOSプロセスで作られ、チップ面積は4.3cm2、54億トランジスタ。消費電力は70~200mW |
なお、TrueNorthチップは256ニューロンを含むコアを4096個並べて作られている。実は、この256個のニューロンは、1つのニューロン回路を時分割で使用して実現されている。
TrueNorthチップは、次の図に示されるように、隣接するチップ間の入力と出力を接続することにより、複数のチップを使ってより大規模なアレイを作ることができるようになっている。後述の、16チップのNS16eシステムはこのようにして作られている。

|
|
TrueNorthチップはチップの周囲に通信用のインタフェース回路が設けられており、隣接ずるチップを接続して大きなアレイを作ることができる |
TrueNorthチップと制御用のFPGAを内蔵したZynQ SoCを搭載したNS1eボードが基本単位で、このボードを16枚 Ethernetで接続したスケールアウト型のNS1e-16システムと16個のTrueNorthチップを4×4に接続し制御用のZynQを付けたスケールアップ型のNS16eというシステムがある。

|
|
1個のTrueNorthに制御用のZynQを付けたNS1eボード、16枚のNS1eをEthernetで接続するNS1e-16システム、16個のTrueNorthを接続して大きなアレイとして使えるNS16eという3種の構成がある |
実行(推論)の場合は、センサからの信号をニューラルネットワークに入力できるデータに変換し、TrueNorthが扱う神経パルス形式に変換する。TrueNorthは入力を処理し、出力をパルス形式からディジタルデータに変換して出力を生成する。

|
|
推論を行う場合の処理フロー。TrueNorthの入出力でパルス形式との変換が行われる |
開発(学習)データフローでは、学習が行われるが、トレーニングの部分の箱にはNVIDIA GPUの写真が貼り付けられており、学習過程の計算は、GPUを使っているようである。

|
|
学習のデータフロー。学習の計算はNVIDIAのGPUで行っているようである |
TrueNorthのニューロンの出力は-1/0/1の値しか取れず、入力の重みも4値の整数からしか選べない。このように低精度の計算しかできないので、重みなどの値に分布を持たせて、これを複数のニューロンを使い、かつ、複数回の計算を行なってその平均を取るというような計算を行なって精度を上げている。しかし、これでは実質的に扱えるニューロン数が減り、かつ、計算時間が長くなってしまう。この問題を軽減する精度の改善法の論文が発表されているが、発表では詳しく触れられなかったので、ここでは省略する。

|
|
TrueNorthのニューロンは低精度であるので、複数ニューロンを使ったり、複数回計算させて、平均をとることで精度を高めている |
モデルの作成では、NVIDIAのGPUを使って学習を行い、学習ができたモデルをTrueNorthのニューロンアレイに落とし込んでいる。ただし、学習の過程ではTrueNorthチップの特性に合わせた最適化を行っている。

|
|
学習はNVIDIAのGPUを使っているが、学習のやり方はTrueNorthに合わせて最適化されている |
TrueNorthのコアは、どれも同じであるので、論理的なコアはどの物理コアに割り付けてもよい。そこで、最適に近い配置を短時間で見つけるツールを開発した。配置の良し悪しは、消費電力や、スループットに影響する。

|

|
|
配置の良し悪しは、消費電力や、スループットに影響するので、最適に近い配置を短時間で見つけるツールを開発した |
コア配置の例 |
次の図はTreuNorthでCIFARデータベースの画像の認識を行わせた例であるが、左のぼけた絵を見て、右側の猫が一番近いと判定している。

|
|
CIFARデータベースの中のぼけた画像を認識した例。猫と判定している |
TrueNorthシステムは、各種のデータベースの画像認識で、認識精度は最高の性能のシステムに迫る精度で、チップの消費電力は0.204Wから1.497Wと非常に小さい。また、スループットは432フレーム/秒から1526フレーム/秒で、430~6100フレーム/Wとエネルギー効率も高い。

|
|
TrueNorthは、認識精度はベストのシステムに迫り、消費電力、認識スループット、エネルギー効率などで、他のシステムより優れている |
エネルギー効率を比較すると、TrueNorthは432-6109フレーム/Wであるのに対して、マンチェスタ大のSpiNNaker(Spiking Neural Network Architecture)は167FPS/W、Titan X GPUは45FPS/W、Core i7 CPUを使った場合は14.2FPS/Wで、TrueNorthは非常にエネルギー効率が高い。ただし、この比較は、まったく同じことをやらせているわけではないので、Apple-to-Appleの比較にはなっていないという断り書きがついている。

|
|
各種の認識システムのFPS/Wの比較 TrueNorthは432-6109フレーム/W SpiNNakerは167FPS/W、Titan X GPUは45FPS/W、Core i7 CPUを使った場合は14.2FPS/W |
空軍の研究所は、NS1e-16システムを使い、手書きの文書を切断して、16台のTrueNorthで並列に認識を行い、大量のノイズの多い生データを処理する研究を行っている。

|
|
NS1e-16を使い、大量のノイズの多い生データを並列に処理する |
ローレンスリバモア研究所は、付加型の製造プロセスの欠陥の検出に取り組んでいる。次の図は、レーザで金属を溶かして貼り付けるという加工を行った結果を見て、穴が開いている、焼き入れが不十分などの箇所を認識する。製造中に欠陥が認識できれば、直ぐにフィードバックが掛けられる。

|
|
レーザによる付加型の加工の欠陥検出 |
16個のTrueNorthでは、大きなニューラルネットを作るにはニューロンが足りない。そのため、次の研究課題は、多数のNS16eボードを高速ネットワークで接続し、現在より、ずっと大きなネットワークを作ることである。このシステムでは、ローカルな情報処理は敷き詰めたTrueNorthで行い、長距離の通信には、EthernetやPCI Expressを使用する。

|
|
次の研究課題は、多数のNS16eボードを高速のネットワークで接続して、大きなネットワークを作ることである |