アシストは10月25日、日本国内で総販売代理店を務めるデータ・プレパレーション・プラットフォーム「Paxata(パクサタ)」日本語版を販売開始した。
Paxataは、HadoopやSparkをベースとし、人工知能、機械学習、インメモリ、コンシューマー・エクスペリエンスといったテクノロジーを活用したデータ・プレパレーション・プラットフォーム。

|
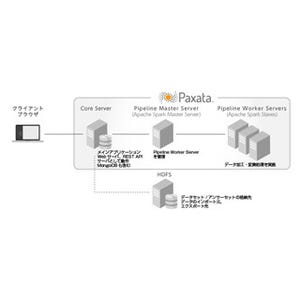
Paxataのシステム構成 |
さまざまな種類やフォーマットのデータソースを追加・格納、データのゆらぎを含め整備・変更、整形、フィルタリング、データ統合、生成データの活用まで、業務に応じてユーザ単位で管理・制限できる。利用したいデータはすべてスプレッドシート上に可視化され、コーディングレスかつポイント&クリックで作業できるため、データの中身を把握しているユーザ部門での利便性が高まり、IT部門における個々の細かいニーズに応じたデータ準備が不要になる。
Paxataのシステム構成|table class="Photo1" width="50" align="center"

|
複数データセットの結合画面例 |
一般的に、目視でデータの中身を精査し精度の高いデータへと加工していく作業は手間と工数が掛かるが、同製品ではAI技術を活用し、さまざまな推奨パターンをレコメンドする。例えば複数のデータセットを結合する場合、データセット内のすべての値を走査し、結合キーの組み合わせをデータのマッチ率と併せて提示したり、フリーフォーマットで書かれたデータ内容が類似している場合、類似データをすべて修正候補として提示する。これにより、ユーザは分析に適したデータを容易にかつスピーディに確定できるという。

|
類似データのグルーピング画面例 |
膨大なデータにさまざまな加工を施しリアルタイムに結果を確認しながらデータセットを作り上げていく一連の処理の最適化を目的として、同製品では、Sparkベースのインメモリ分散処理エンジンとデータセットを格納するストレージにスキーマレスなデータ管理が可能なHDFSを採用している。また、Paxataで加工した精度の高いデータをETL/EAIツールと連携させ全社で再利用可能にすることでデータ活用の拡大が図れるとしている。
提供価格(税別)は、16コア960万円(使用権+サポートの年間サブスクリプション)、追加は1コア60万円となる。
同社は今後、直販に加えビジネスパートナー経由での活動に注力し、2017年12月末までに30社への導入を目指している。