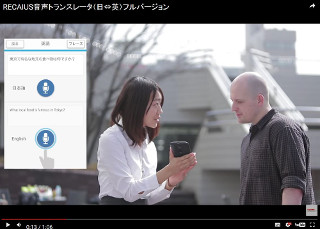
東芝は10月25日、複数の人が同時に話しても、会話と同時に正確な聞き分けを行い、話者ごとに集音できる分離集音技術を新開発した。
近年の音声認識性能の向上により、会議や接客の会話をテキスト化して業務の改善・効率化に役立てたいというニーズが高まっているという。しかし、複数の人が同時に発言すると音声認識精度が低下する問題があった。また、同時発言を分離する技術の開発も進められているが、会話している場所の音響特性や話し手の位置といった録音環境に対して最適な分離性能を得るためには、数十分程度の録音を行う必要があった。

|
分離集音技術 |
そこで同社は、事前の録音を行うことなく、複数の人が同時に話した音声でも話者ごとに集音できる分離集音技術を開発した。同技術により、1つの音声入力機器の中に複数のマイクを搭載したマイクロホンアレーを用いて、高い精度で話者ごとの音声を認識しテキスト化することが可能となる。高い精度でテキスト化した音声データは、会議での議事録作成の負担軽減や、接客時の顧客分析やスタッフの応対マニュアルの改善に役立つという。また、訪日外国人向けの自動翻訳にも適用可能だとしている。
従来の音源分離技術では、音源(話者)ごとに分離するフィルタをシステムが学習するために、数十分程度録音した後でなければ十分な分離精度が得られないという課題があった。そこで同社は、フィルタを直接学習するのではなく、マイクからみた話者の位置情報を表す空間特性を学習することで、環境にあわせて時々刻々とフィルタを更新させることで高精度に分離する方式を新開発した。分離の正確さは従来技術と比べて約2倍に向上しているほか、話者からそれぞれのマイクまでの音の到達時間差などの音源方向に関する対応表とのマッチングにより、話者の相対的な位置関係を高速に判定する。これらの特長により、会話する場所で事前録音を行わなくても、同時に話された音声を話者ごとに分離集音することが可能となった。
同社は今後、同社のクラウドAIサービス「RECAIUS(リカイアス)」に、同技術を2017年度中に搭載することを目指して研究開発を進めるとしている。