2011年6月にTop500で世界一になった京コンピュータは現在、中国の天河2号や太湖の光などに抜かれて世界的には5位に後退したが、国内では引き続き1位であった。しかし、東京大学と筑波大学が共同で導入するピーク性能25PFlopsの「Oakforest PACS」というスパコンが、今年12月に稼働する計画になっており、国内でも2位になると見られる。
|
|
|
Oakforest PACSスパコンについて発表する東大の塙 准教授 |
筑波大学で開催されたシンポジウムにおいて、東京大学 情報基盤センター スーパーコンピューティング研究部門の塙 敏博准教授がOakforest PACSスパコンについて発表を行った。
筑波大、東大、京大の3大学は共通仕様に基づく「T2K(3大学の頭文字を並べたもの)」というスパコンを開発し、2008年から学内外のユーザに提供してきた。この後継となるのがOakforest PACSスパコンである。今回、京大は参加していないが、筑波大と東大の近さを生かして、T2Kの時の共通仕様から一歩進めて、両大学が費用を出し合って1台のスパコンを調達したのがOakforest PACSスパコンである。
このスパコンは、筑波大と東大 本郷キャンパスの中間地点となる東大 柏キャンパスに設置される予定である。柏という地名から、富士通のFX10を使う第1世代のスパコンはOakleaf(柏の葉)という名前が付けられ、第2世代にあたる今回のシステムはOakforest(柏の森)という名前が付けられている。それに筑波大の開発してきたPACSスパコンの命名を組み合わせてOakforest PACSという名前になっている。
「JCAHPC(Joint Center for High Performance Computing)」の調達ポリシーは、オープンな最先端技術を採用し、超並列なPCクラスタを作る。ただし、広範なユーザが使い易いようにGPUは使わないというものである。そして、2大学の共同調達で、予算額を増やして超大規模計算も実行可能な規模を実現するというものである。

|
|
調達ポリシーは、オープンな最先端技術を採用し、超並列なPCクラスタを作る。2大学の共同調達で、超大規模計算も実行可能な規模を実現 (この記事のすべての図は塙准教授の発表スライドを撮影したものである) |
Oakforest PACSスパコンは、IntelのXeon Phi(Knights Landing)を計算エンジンとして使うメニーコアスパコンである。Knights LandingのコアはXeonと命令互換で、OSを走らせることができる。そして、各コアは64ビットの倍精度浮動小数点演算なら8個並列に処理できるAVX-512というベクトル処理命令をサポートしている。
つまり、Oakforest PACSスパコンは、OSを走らせることも、スパコンのベクトル演算を行うことができるプロセサコアを55万8144コア備えるメニーコアスパコンであり、ソフトウェア的にはPCクラスタのように使えるので、CPU+GPUのようなプログラミングの難しさが無く、広いユーザが使えるという。
ピークの倍精度浮動小数点演算性能は25PFlopsであり、これは10.5PFlopsの京コンピュータの2.5倍に近い性能である。また、Knights LandingはMCDRAMという実効バンド幅490GB/sという高速のメモリを備えている。ただし、MCDRAMは、16GBと容量が限られる。
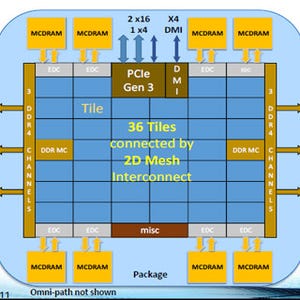
Oakforest PACSスパコンは、全体で8208個のKnights Landingを使い、IntelのOmni-PathのFat-treeネットワークで接続する。

|
|
Oakforest PACSスパコンは、68コアのXeon Phi 7250を8208個使用し、ピーク倍精度浮動小数点演算性能は25PFlops。100GbpsのIntelのOmni-Pathを使って、フルバイセクションの相互結合網を使う |
このフルバイセクションバンド幅のFat-tree網は、12台の768ポートのディレクタスイッチと362台の48ポートのエッジスイッチで構成されている。ディレクタスイッチとエッジスイッチの間は2リンクを並列に使うFat-tree接続になっており、ポートの衝突がなければ、全ノードが同時に通信を行うことができるネットワークになっている。

|
|
Fat-tree網は、12台の768ポートのディレクタスイッチと362台のエッジスイッチで構成される |
ストレージとしては26.2PBのDDN製のSFA14KEディスクと940TBのIME14Kファイルキャッシュシステムを持っている。ファイルキャッシュのバンド幅は1.56TB/s、ハードディスクのSFA14KEの方は500GB/sである。
総消費電力は4.2MWで、これは冷却用の電力を含んだ値であるという。京コンピュータは10.5PFlopsで12.66MWで、これは冷却を含まない値であるので、電力は1/3以下で、ピーク性能は約2.5倍に改善している。そして、Oakforest PACSスパコンのラック数は102本である。これも京コンピュータが計算ノードだけで800本以上のラックを必要とし、ストレージを加えると1000本を超えていたのと比べると1/10以下となっている。

|
|
Oakforest PACSスパコンは、26.2PBのストレージと940GBのファイルキャッシュを持つ。ファイルキャッシュのバンド幅は1.56PB/s。消費電力は4.2MWで、これは冷却を含む値である。ラックの本数は108本と京コンピュータの1/10以下 |
ハードウェアは富士通製で、次の図の右側に示す2Uのシャーシに8台の計算ノード(左)を収容する。Knights Landingは水冷で、ASETEKのオレンジ色の水冷のコールドヘッドが付いているのが見える。なお、DIMMなどの部品は空冷となっている。

|
|
左がKnights Landing(KNL)1個を搭載した計算ノードボード。KNLは水冷である。右は前後から各4枚のノードボードが入る8ノード収容の2Uシャーシ |
計算ノードのOSとしては、ログインノードなどはRed Hat Linux、I/Oなどを行う計算ノードはRed Hat互換のオープンのCentOSを使う。しかし、純粋な計算ノードは理研AICSで開発中のOSノイズの小さいMcKernelを使うとのことである。
コンパイラは、gccやIntelのXeon Phi用コンパイラに加えて、筑波大と理研で開発中のpgas言語であるXcalableMPコンパイラを使う予定である。

|
|
計算ノードのOSはCentOSとMcKernelと呼ぶ理研AICSで開発中のメニーコアOS。コンパイラはgcc、Intelに加えて筑波大、理研で開発しているXcalableMPを使う |
Oakforest PACSスパコンは、ハードのこの部分が東大、ここからは筑波大というようなハードウェアの分割は行わず、負担費用に応じてCPU時間を割り当てるという柔軟な運用を行う。また、時間を限って、全系を使ってゴードンベル賞を狙うような大規模計算も可能にするという。さらに、夏季の節電要請に対応して、電力に上限を設けるような運用も考えている。
10月1日には400ノード程度での運用を開始しており、12月1日からの全系稼働を予定している。その後しばらくは限定ユーザの使用で問題の洗い出しと修正を行い、来年4月から一般ユーザへの解放を予定している。なお、12月2日には運用開始を祝う式典が催されるとのことである。
なお、撮影禁止という条件で、9月29日の設置状況の写真が示されたが、大部分のラックは設置済みであるが、まだ、少し工事が残っているという感じであった。

|