Hot Chips 28において、IBMは「POWER9」プロセサを発表した。
|
|
|
Hot Chips 28でPOWER9プロセサを発表するIBMのBrian Thompto氏 |
IBMは2010年には「POWER7」、2012年に「POWER7+」、2014年には「POWER8」を出し、2017年後半にPOWER9を出す予定である。POWER9は14nmプロセスで作られ、SMT8スレッドのコアを最大12コア搭載する。実は、このコア数はPOWER8と同じであるが、処理能力は大きく向上している。

|
|
IBMのPOWERプロセサのロードマップ。POWER9の登場は2017年の後半 (この記事のすべての図は、Hot Chips 28でのThompto氏の発表資料のコピーである) |
POWER9はDeep Workloadに最適化されており、新たに展開しつつあるアナリティックスやコグニティブなどの大量のデータを処理して知識を抽出するようなアプリケーションに向けて最適化を行っているという。もちろん、POWER9は、従来からのHPCやクラウドデータセンタ、企業の基幹システムもカバーする全方位のCPUである。

|
|
POWER9はディープワークロードに最適化しているが、従来の用途もカバーする全方位CPUである |
POWER9は14nm FinFETプロセスで作られ、トランジスタ数は80億個。17層配線というところが物凄い。また、eDRAMであるが120MBという驚異のキャッシュ容量を誇る。

|
|
14nm FinFETプロセスで作られ、トランジスタ数は80億個。17層の配線層を持つ |
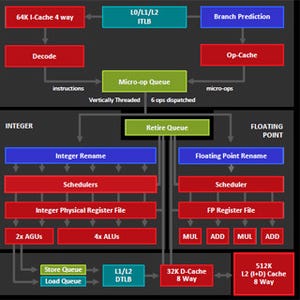
POWER9は4スレッドのSMT4と8スレッドSMT8の2つの構成が取れる。SMT4はLinuxエコシステム向き、SMT8はPowerVMエコシステム向きである。さらに、DIMMを直結するスケールアウト型システム向きの構成と、バッファチップを経由して大容量のメモリを持たせるスケールアップ型のシステム構成も選べる。

|
|
Linux向きのSMT4×24コアの構成とPowerVM向きのSMT8×12コアの構成が選べる。また、メモリも8DIMMチャネル直結と、バッファチップ経由の大容量メモリ構成が選べる |
POWER9ではスレッド性能を強化している。そして、SMT8とSMT4という2種の構成が選べる。実行資源であるVSU(Vector Scalar Unit)やLSUはSMT8では8個、SMT4では4個となっている。IntelのXeonコアやAMDのZenコアは、1つの実行資源を2つのSMTスレッドで共用しているが、POWER9はスレッドごとに1つの実行資源を持っているので、スレッドの実行性能は、XeonやZenより、格段に高いと考えられる。

|
|
SMT8は実行資源であるVSUやLSUを8組、SMT4は4組とスレッドごとに実行資源を持っている |
POWER9のコアはVSU、LSU 1組の64bitスライスが基本で、それを2つ繋いだ128bitスライスを作り、さらに2つの128bitスライスを並べたスーパースライスがSMT4コアとなる。また、4個の128bitスライスを並べるとSMT8コアのスーパースライスができるというように、モジュラーな設計となっている。

|
|
VSUとLSU 1個ずつの64bitスライスが基本で、それを並べることにより、128bitスライスを作り、2個の128bitスライスでSMT4コア、4個の128bitスライスでSMT8コアを作るモジュラー設計になっている |
POWER9では、命令のフェッチから実行開始までのパイプライン段数を5段も縮めている。これは、条件分岐が起こったときに次の命令がフェッチされて実行を開始するまでの時間が5サイクル短くなるので、分岐が多いプログラムの性能が改善する。また、分岐予測も改善されているという。

|
|
命令フェッチから実行開始までのパイプライン段数を5段短縮している |
SMT4コアは、32KBの命令キャッシュから、8命令を読み出し、6命令をデコードする。1サイクルの分岐命令の実行は1命令だけである。VSUは4個のALUと4個のFPユニットを持つ。POWER9で新しいのは、128bit長の4倍精度FPと4倍精度の十進のDecimal FPの実装である。筆者の知る限りでは、4倍精度の浮動小数点演算をハードで実行するプロセサは、これが初めてである。

|
|
SMT4コアは6命令デコード。ALUとFPユニットはそれぞれ4個を実装する。新しいのは128bit長の4倍精度FPと十進FPの装備 |
POWER ISA3.0ではIEEE 754 の4倍精度FPと4倍精度十進FPをサポートする。これらは金融、セキュリティ関係で使われるという。一方、半精度のサポートは、データ形式の変換だけで、演算自体はサポートされていない。その他にも、新しい使い方をサポートする演算命令や乱数発生命令の追加やメモリアトミック、ガーベッジコレクションのサポート命令などが追加されている。

|
|
ISA 3.0ではIEEE 754の128bit長の4倍精度FPと4倍精度十進FPがサポートされる。一方、半精度はデータ形式変換だけのサポートである |
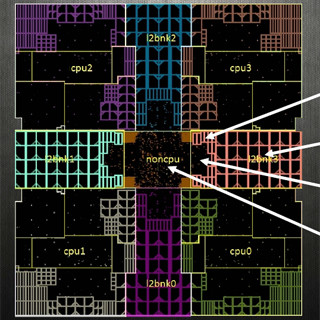
POWER9のキャッシュは圧巻である。10MBのバンクが12個並び、120MBの容量と7TB/sのスイッチを持つ。この巨大な高バンド幅のスイッチを作るには17層という金属配線を使っている。IntelのXeonの配線は10層程度であるのと比べると、ものすごい配線層数である。

|
|
L3キャッシュは10MBのバンクが12個並ぶ。そして、DRAMメモリやI/Oとの接続には7TB/sのスイッチを持つ |
POWER9は8チャネルのDIMMを直結するという構成と、バッファチップを経由して大量のDIMMを接続するという構成が選択できる。大容量構成では1個のPOWER9に最大8TBのメモリを接続することができる。そして、POWER8と同様にメモリのエラー訂正やリカバリは充実している。

|
|
DIMM直結の構成と、バッファチップ経由でDIMMを接続する構成が選択できる |
POWER9の性能であるが、POWER8の性能を1.0としてFloatの性能は1.6倍程度であるが、その他の多くの分野の処理では、1.8倍から2.0倍の性能となっており、グラフ解析では2.2倍を超える性能となっている。ただし、これは両者のクロックが同一の場合の比較となっている。しかし、POWER9のクロック周波数は公表されていないので、システムの性能がこの比率になるかどうかは分からない。

|
|
同一クロック周波数でのPOWER8との性能比較。1.6倍から2.2倍の性能となっている |
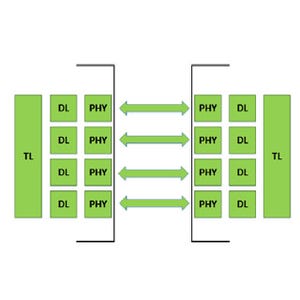
また、POWER9はI/Oやアクセラレータの接続インタフェースも充実している。PCI Express Gen4を48レーン持ち、総バンド幅は192GB/sに達する。そして、「IBM BlueLink」と呼ぶ25Gbit/sの伝送を行うリンクを48レーン備え、300GB/sの接続を可能にしている。
そして、CAPI(Coherent Accelerator Processor Interface) 2.0はPOWER8の4倍のバンド幅となり、NVIDIAのGPUを接続するNVLinkも2.0のサポートとなっている。NVLink2.0はキャッシュコヒーレンシをサポートすると言われていたが、今回の発表では、コヒーレンシに関しては触れられていない。

|
|
48レーンのPCI Express Gen4を持ち、192GB/sのバンド幅でI/Oを接続する。また、48レーンのIBM BlueLinkは300GB/sのバンド幅を持つ |
まとめであるが、POWER9プロセサは、IBM Watsonのような認知技術(ビッグデータと学習)などの新しい用途に向けた新時代のCPUである。プロセサコアとチップのアーキテクチャをこれらの用途に向けて最適化している。
スケールアウトとスケールアップの両方の使い方に対応できる、可変の構成が選べるようになっており、アクセラレータの接続機能も充実している。と述べて発表を締めくくった。

|
|
POWER9は、認知科学の時代に向けたコアとアーキテクチャのプロセサ |