次のグラフはTCAの2つのノードのGPUに間を往復するピンポン通信を行った場合のレーテンシを示している。データサイズが小さい場合、CPU間のPIOでは0.8μs、CPU間のDMAでは1.8μs、GPU間では2.0μsとなっている。
これに対して「MVAPITCH2」でGPU Directを使った場合は4.5μsでPEACH2に比べて2倍以上の遅延となっている。しかし、MVAPITCH2の開発者であるオハイオ州立大のD.K.Panda教授は、質疑の時に、「最新版ではもっと速くなっている。最新版で比較すべき」とクレームを付けていた。実は、Panda先生はこの次の発表者で、その発表ではMVAPITCH2-GDR2.1aでは(次の図で使用した)2.0bに比べて遅延が0.4倍に小さくなり、4KBのデータサイズの場合で2.37μsとTCAに負けない性能となっていた。

|
|
ピンポン通信で測定したデータサイズと通信遅延の特性。8バイトの場合、PIOは0.8μs、DMAでCPU間は1.8μs、GPU間は2.0μsである |
次の図はDMAで複数のPEACH2を通過する伝送を行った場合の通信遅延を測定したもので、PEACH2を通過するごとに200~300nsの時間が掛かっていることが分かる。

|
|
PEACH2を複数通過する場合の遅延の増加は、PEACH2 1個当たり200~300ns |
次の図はピンポン通信を行った場合のデータサイズとバンド幅の特性を示すものである。一般に、プロトコルのオーバヘッドがあるので、データサイズが小さい場合はバンド幅は低く、データサイズの増加とともに増えて行く。そして十分データサイズが大きくなると、ハードウェアの転送能力などで決まる値で飽和するという特性を示す。
CPU間のDMA転送の場合は、3.5GB/sで飽和しており、これはPCIe2.0の理論値の95%のバンド幅であり、十分高速である。GPU間の場合は最大では2.8GB/sとなっているが、何故か最大データサイズでは2.5GB/sに低下している。ここでも1MB以下のデータサイズではMVAPITCH2-GDR2.0より速いと述べているが、Panda先生の発表では、最新のGDR2.1aでは性能を2.2倍に向上させ4KBのサイズで2.9GB/sが出ていた。このあたりはなかなか厳しい戦いである。

|
|
DMA転送のデータサイズとバンド幅の特性 |
なお、DMA(QPI、GPU)というカーブがあるが、これはQPIを通してPEACH2が接続されていない方のCPUに接続されたGPUにデータ転送を行った場合の特性で、300MB/s程度で飽和しており、使い物にならないほど遅い。また、その上のDMA(SB、GPU)はCPUに内蔵されているPCIeスイッチを経由して、同一CPUに接続されたGPU間をDMA転送した場合の特性で、QPI経由よりはかなり良くなっているとは言え900MB/s程度で、これも十分な性能が得られない。このため、TCAではPEACH2を使う転送はPEACH2と同じCPUに接続された2台のGPUに限定している。
MPIの通信は、1対1の通信だけでなく、全ノードからデータを集めて結果を全ノードに広報するAllgatherや全ノードの結果の合計などを計算し、その結果を全ノードに広報するAllreduceなどの集合通信と呼ばれるものがある。
次の2つの図は、AllgatherとAllreduceの実行時間を示すもので、データの集め方、広報の仕方としてRing、Neighbor Exchange, Recursive doubling、Disseminationの4種のアルゴリズムを使った場合とMPIを使った場合を比較している。そして、ノード数が2、4、8、16の場合の測定を行っている。
Allgatherで集めるデータは128KBとしており、Recursive Doublingが良い結果を出しているが、16プロセスの場合はMPIの方が多少速いという結果になっている。
Allreduceは8Bのデータを全ノードから集めて、合計などを計算している。この操作はレーテンシが効く操作で、MPIに比べてPEACH2の方が速い。集めるアルゴリズムとしてはDisseminationが最も速いという結果となっている。

|

|
|
左がAllgather、右がAllreduceの性能。PEACH2ではRing、Neighbor Exchange、Recursive Doubling、Disseminationの4種の通信アルゴリズム、そしてMPIとの比較を行っている |
|
そして、次の2枚の図は、QUDAという格子色量子力学のライブラリを使った処理で、マルチGPUのノードで、CG法を使って連立1次方程式を解いている。2~16ノードの範囲で、ノードの配列を変えて、MPIによるP2P(Peer-to-Peer)通信、MPIのリモートメモリアクセスとTCAを使った場合の所要時間を棒グラフにしている。
上側の16の4乗という大きいモデルでは4ノードではMPIとTCAの性能はほぼ拮抗しているが、8ノード以上になるとTCAの方が多少速いという結果になっている。下側の8の4乗のモデルではTCAの方が明らかに速く、(2,4)ノードの場合、MPI-P2Pの1.96倍の速度となっている。

|

|
|
格子色量子力学用のQUDAライブラリを使った場合の処理時間の比較。ノード構成とMPIによるPeer-to-Peer通信、MPIによるRemote Memory AccessとTCAを使う場合の処理時間を比較している |
|
まとめとして、TCAによりアクセラレータを直結するテクノロジの有効性を確認した。具体的には、PEACH2により最大3.5GB/sと理論性能の95%に達するバンド幅が得られ、小さいデータではCPU間のPIOでは0.8μs、GPU間のDMAで2.0μsと短い遅延が得られた。集合通信ではAllgatherではあまり効果が見られなかったが、AllreduceはMPIの半分程度の時間で行うことができた。QUDAではメッセージサイズが小さい場合、PEACH2は良い結果を示しているが、実行時間の短縮までは示すことが出来なかったという。

|
|
まとめ。PEACH2を使う通信は、MPIよりも遅延が小さく、大部分の領域でバンド幅も大きくなり、アクセラレータをPCIeで直結するというやり方の有効性を示した |
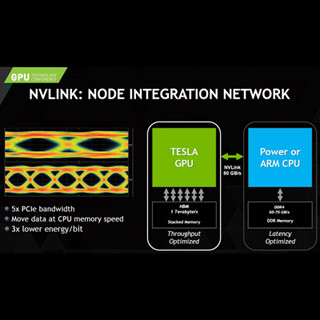
ただし、Panda先生の最新版は大幅な性能向上が行われており、InfiniBandを使うMPIの性能も上がってきている。また、NVIDIAは独自のPCIeより高性能のNVLINKを次世代のPascal GPUからサポートする計画であり、独自のインタコネクトを作ることの必要性は薄れてきているのではないかと思われる。
しかし、アクセラレータ間に高速、高バンド幅の通路を持つことが有効であることが、ピーク性能364TFlopsという規模のスパコンで実証されたことは、研究として意義があると考えられる。