NVIDIAはGPUに最適化したライブラリを各種、開発、提供しているが、その一環として、Deep Neural Network(DNN)開発用の「cuDDN」というライブラリがある。このcuDNNの概要がGTC 2015で発表された。なお、cuDDNは昨年9月に第1版がリリースされ、現在は改良版の第2版がリリースされているという状態である。
DNNの開発は、U.C.BerkeleyのCaffe、モントリオール大のTheanoなどのフレームワークを使えば、基本的な機能はライブラリの呼び出しだけで記述でき、詳細な機能をプログラムする必要はないので、大幅に省力化できる。しかし、これまでは、それぞれのフレームワークのGPU対応は個別に行われており、効率が悪かった。
cuDNNはDNNで使われる基本的な機能をまとめたCUDAライブラリであり、すべてのフレームワークから簡単に呼び出して使えるということを目的としている。これにより、フレームワークごとにCUDAコードを書くという無駄が省け、NVIDIAが最適化したライブラリを提供するので、性能的にもよいものができる。

|
|
cuDNNは、DNNフレームワークごとにGPUコードを書く無駄を省き、共通に使えるCUDAライブラリを目指している |
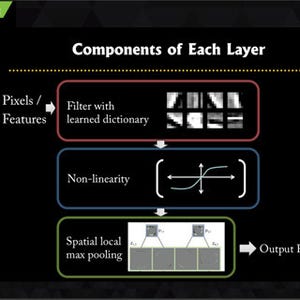
DNNの各層の処理は、入力画像とフィルタのConvolutionを計算し、2×2や3×3の小領域の最大値を取るMax Poolingを行い、その値をActivation関数という非線形な関数で変換するという処理となる。
中でも、Convolutionの計算が大部分で、80~90%の実行時間を占める。従って、この部分の高速化が重要である。

|
|
DNNのConvNets層はConvolution、Pooling、Activationの3つの機能を持つ。中でも、Convolution計算の部分が80~90%の実行時間を占める |
cuDNNの設計目標は、DNNのDeep Learningに必要な機能を提供し、多様なデータ格納形式に対応できる柔軟性を持ち、性能と使用メモリ量のトレードオフができるようにすることである。メモリに余裕がある場合は、ワーク領域をたくさん使っても性能を上げる方が良いが、メモリがきつい場合は、性能はある程度犠牲にしてもメモリを使わないことが重要である。このように色々な状況に応じて最適な機能を提供するわけである。

|
|
cuDNNの設計目標は、DNNの基本機能の提供、データ配置の柔軟性、ワークスペースのメモリ量と性能のトレードオフができるということである |
cuDNNの第1版をcaffeに組み込んだ結果を次の図に示す。この結果はAlexNetの学習の例である。誤差を出力から入力に伝搬させて学習を行うBackward Propagationの処理が一番時間が掛かっており、156,270秒掛かっていたが、cuDNNの使用で120,651秒と1.3倍にスピードアップされている。そしてForward Propagationでは109,310秒が75,330秒と1.45倍になっている。この結果、cuDNNの使用で、全体では1.36倍のスピードアップが得られている。

|
|
Caffeを使ったAlexNetの学習時間の比較。cuDNNの使用で、1.36倍のスピードアップが得られた。 |
Convolutionの計算が主要な処理であるが、その計算にはいろいろなパラメータがある。学習には何万枚かそれ以上の画像が使われるが、ミニバッチとよぶ数10枚から1024枚程度の画像を一まとめにして処理するのが一般的である。これがMinibatch Sizeである。そして入力となる(直前の層の出力である)Feature Mapが何枚あるのか? (入力画像の場合はRGBで計3枚)画像全体の縦横のサイズ、何種類のフィルタを使って何枚のFeature Mapを出力するのか、フィルタカーネルの縦横サイズ、ゼロを詰め込む半端部分のサイズ、フィルタの縦横のずらし量の指定が必要である。
さらにデータがどのように格納されているかのバリエーションがあるので、全てのケースに対応し、性能が出るようにライブラリを作るのはかなり大変である。

|
|
Convolutionの計算には11項目のパラメータがあり、データの格納法にもバリエーションがあり、すべての組み合わせに対応し、高い性能を提供するのは大変である |
Convolution(畳み込み)の計算はデータを行列の形に格納しなおして、行列積として計算する、FFTを使って周波数領域のデータに変換して計算する、元のデータ格納形式のまま、畳み込みを計算するなどの方法が考えられる。
行列積として計算する方法(GEMM)は安定して高性能が得られるが、並べ替えた行列を格納するため多くのメモリを必要とするという問題がある。FFTは大規模な処理では効率が高いが、これもメモリを多く必要とし、フィルタをずらす部分の処理が難しい。直接、畳み込みを計算する方法は、メモリのオーバヘッドは無いが、各種のケースに対して最適化するのが難しいというように一長一短がある。

|
|
行列の形に並べ替えてGEMMを使う、FFTを使って計算する、並べ替えをせず、直接、畳み込みを計算するなどの方法があるが一長一短である |
2D ConvolutionはImageにFilterを重ね、対応するピクセルの値を掛けて、総和をとる。この例ではフィルタは3×3であるが、実際には10×10とかもっと大きいサイズが使われる。イメージの中に枠で示された部分にフィルタがある場合は、次の図の右側のように枠内のピクセルを行ベクトルに並べ替え、フィルタを列ベクトルに並べ替えて内積を計算すれば良い。

|
|
イメージの枠内の部分を行ベクトル、フィルタを列ベクトルにして内積を取る |
そして、フィルタを当てる領域を右に1ピクセルずらせて同じ操作を行う。

|
|
フィルタをあてる領域を右に1ピクセルずらせて同じ操作を行う |
これを繰り返すと、イメージ側の行ベクトルが増えて行き、行列×ベクトルの計算になる。

|
|
フィルタをあてる部分をずらすと行ベクトルが増え、行列×ベクトルの演算になる |
実際のDNNの処理では、1つの画像にいくつものフィルタが適用され、さらにミニバッチの数だけの異なる画像を一括して処理する。そのため、行列×行列の計算となるのでGEMMが使え、より高い演算性能が得られる。なお、ここでは紙面の都合でフィルタは2×2で描かれている。

|
|
実際には1つの画像に多数のフィルタが適用され、ミニバッチに含まれる数10枚以上の画像が一括して処理されるので、行列×行列の計算が使える |
そうすると、もとのイメージやフィルタの行列をGPUのシェアードメモリに転送してやれば、LINPACKなどで長年にわたって最適化されてきた行列積の計算法が使える。このやり方では、GPUのシェアードメモリにデータを転送するときに並べ替えを行ってやれば良い。しかし、イメージの格納形式やストライドの違いなどがあり、並べ替えのアドレス計算に手間が掛かる。

|
|
シェアードメモリへの転送と同時に並べかえを行えば、余計なメモリは不要で効率が良い |
しかし、どのアドレスのデータをどこに持っていくかは、データの格納方法やストライドに依存するのでアドレス計算に手間が掛かる。

|

|
|
このアドレス計算は割り算ではなくシフトと掛け算を使うなどで、ある程度簡単にできる |
第1版のcuDNNとオリジナルのcaffeで書かれたAlexNetの性能比較。ミニバッチのサイズが小さい場合は差が無いが、16以上になるとcuDNN版が速く、128では30%程度速い。Convnet2の実装は128では速いが、ミニバッチサイズが小さい領域では遅い |
別の方法としては、並べ替えのインデックスは事前に計算しておき、それを見て並べ替えを行うという方法がある。

|
|
毎回アドレス計算を行うのではなく、あらかじめ計算した並べ替えをバッファに格納しておく。多少メモリは必要になるが、毎回計算する必要はない |
この手法をAlexnetとOverfeatに適用した結果が次の図である。1層目では性能はあまり上がっていないが、2層目以降では47~48%と大きな改善が得られている。

|
|
事前に並べ替えテーブルを作る手法での性能アップ。第1層ではあまり大きな改善は無いが、2層以降では47~48%と大きな改善が得られている |
cuDNNの呼び出しでは、どのアルゴリズムでConvolutionを計算するかを直接指定することもできるが、NO_WORKSPACEを選ぶとワークスペースを使わない直接法が使われ、PREFER_FASTESTを選ぶと、必要なワークスペース量は気にせず、一番早いアルゴリズムが使われる。さらに、SPECIFY_WORKSPACE_LIMITを選ぶと、ワークスペースとして使用できるメモリの上限を指定することができ、ライブラリはその範囲内で性能が最高になるアルゴリズムを選んでくれる。

|
|
どのアルゴリズムを使うかの指定もできるが、この図のようにNO_WORKSPACE、PREFER_FASTESTとWORKSPACE_LIMITを指定する方法も使える |
現状では、まだ、最適化されていないが、cuDNNでは3DのConvolutionもサポートされている。

|
|
cuDNN V2ではまだ最適化されていないが、3DのConvolutionもサポートされている |
今後の計画であるが、Maxwell GPU向けの最適化が優先順位が高い。そして、3Dの機能の充実、Local Response Normalization機能のサポート、FFTによる畳み込みの検討などを考えているという。

|
|
当面、Maxwell GPU向けの最適化を行う。さらに、3D機能の充実、LRNサポート、FFTを使うConvolutionの検討などを考えている |
cuDNNは、まだ、歴史が浅いが、今回のGTCに見られるようにNVIDIAはDeep Learningに力を入れており、開発が強化されていくと思われる。