2014年11月のGreen500では、ドイツのGSI Helmholtz Centerの「L-CSC」というマシンが5,271.81MFlops/Wで1位、高エネルギー加速器研究機構(KEK)の「Suiren(睡蓮)」は4,945.63MFlops/Wで、惜しくも2位となったが、このほど、ExaScalerとPEZYは、HPLプログラムの改良により、L-CSCの記録を上回る性能/Wを達成したと発表した。
Green500は実行性能/消費電力で求められるエネルギー効率でスーパーコンピュータ(スパコン)のランキングを行っている。実行性能MFlopsは、Top500と同じHPL(High Performance Linpack)で計測された性能であり、それをLinpackを実行している時の消費電力Wで割る。
この電力の測定であるが、コンピュータの消費電力は動作状態で変化する、また、消費電力の大きいスパコンは壁のコンセント1個では電源を供給できず、多数の電力計を必要とする。このため、Green500の電力測定には3つのレベルの測定法が規定されており、そのなかで一番測定が容易なLevel 1という基準が使われることが多い。
Level 1では、システムの一部(ただし、全体の1/64以上)の電力を実測するだけで良く、また、HPL実行期間の開始直後の10%と終了直前の10%の期間を除いた部分の内の20%の時間の消費電力を計測すれば良いという規定になっている。

|
|
Linpack実行時の消費電力の変動の例 |
この図に示すように、HPL実行時の消費電力は、終了に近づくと減少するのが一般的で、開始から70%~90%の時間で電力を測ることで計測上の消費電力を減らし、高いMFlops/W値を登録するということが一般的に行われている。
しかし、これはおかしいということから、Green500のユーザグループでは、HPL実行の一部ではなく、全区間の平均消費電力を使うべきという意見がでている。2014年11月にGreen500で1位となったL-CSCはこの全区間の平均の消費電力を使っており、消費電力が減る70%~90%区間の消費電力を使うと6,010MFlops/Wになると発表された。
一方、2位となったExascaler-1の結果は、70%~90%区間の消費電力を使い、また、消費電力にはノード間を接続するInfiniBandスイッチの電力を含まないというものであり、Level 1の規定に合致しているのは当然であるが、L-CSCとの実力の差は20%以上存在した。
これに対して、2014年11月のGreen500の発表以降、ExaScalerは睡蓮でのHPLプログラムの改善を続け、このほど、70%~90%区間の電力を使うと6217MFlops/W、全区間の電力を使った場合でも5,452MFlop/Wと、L-CSCの6010/5272MFlops/Wを上回る性能を達成したと発表した。
2014年11月から25%あまりスコアを改善した主因はソフトウェアのチューニングであり、ExaScaler-1のハードウェアはまったく変わっていない。
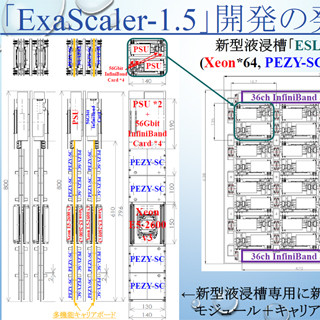
Exascaler-1の1つのノードの構造は次の図のようになっており、睡蓮システムでは、左側のIB(InfiniBand)のネットワークインタフェースから32ノードを接続するIBスイッチに接続されている。

|
|
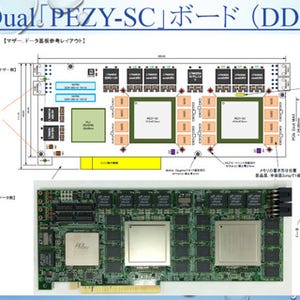
ExaScaler-1の1ノードの構成。係数行列をすべてPEZY-SCのメモリに格納し、メモリ間転送のデータ量を削減 |
HPLの計算は、係数行列の左辺と上辺を計算し、その結果を使って、残りの部分をアップデートするという処理の繰り返しになるが、計算量としては残りの部分のアップデート計算が主要な計算処理となる。従って、この部分をアクセラレータに担当させるようにプログラムを書くことになる。しかし、この計算のためにはその時点での行列全体のデータを(分割して)アクセラレータに転送し、アクセラレータでの計算が終わると、残った行列の全部のデータを(分割して)アクセラレータからホストCPUのメモリに転送する必要がある。
これに対して、元の行列をCPUのメモリではなく、PEZY-SC側のデバイスメモリに格納するようにHPLプログラムを書き換えることにより、必要な転送データ量を削減した。
行列をデバイス側のメモリに置くという計算法は2008年にTop500の1位となったRoadrunnerでも使われており、PEZY-SCでの独創ではないが、PEZY-SCの場合はDDR3 DRAMを使い32GBのメモリを登載しており、CPUメモリとの転送データ量をより少なくすることができるので、効果的である。また、デバイス側のメモリを使うことにより行列のサイズを896000元から960000元に増加させることができ、これも性能向上に貢献している。これらの改善によりLevel-1でのGreen500のスコアは6,217MFlops/W と25.5%向上し、Linpack性能も202.64TFlopsと13.8%向上している。