NTTレゾナントは12月3日、日本語解析技術に関するAPIを「gooラボ」で公開した。同技術は、NTT研究所が開発し、長年「goo」にて利用してきたもの。
今回は第1弾として、ビッグデータ解析などにおいて必須となる要素技術「語句類似度算出」「ひらがな化」「固有表現抽出」「形態素解析」の日本語解析API4種が公開された。
語句類似度算出とは、2つの語句(キーワード)に対して、構成単語や音素の情報を踏まえて、その類似度合いを算出するAPIで、今まで目視や辞書を使って行っていたデータの統合作業を自動化する。

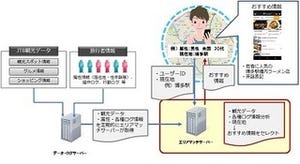
|
語句類似度算出APIの仕組み |
固有表現抽出は、トレンドや評判の解析に必須となる人名や地名、組織名などを抽出するAPIで、SNS上の投稿で話題になっているスポットを発見するといった分析を容易にする。
これらAPIの活用により、分析対象となるビックデータが日本語で書かれた文章の場合、単なる文字列の集計に加え、より書かれている内容に基づいた分析ができるようになるという。
ひらがな化は、字混じりで書かれた文字列を”ひらがな”もしくは“カタカナ”による記載に変換するAPIで、変換後の文字列は、読みやすいように文中の適当な位置に半角スペースが挿入されるので、子供向けコンテンツの作成などに有用。
形態素解析は、日本語の文字列を、形態素と呼ばれる単位に分割するAPIで、その結果を集計することにより、自社製品のレビュー記事からどのような表現でよく評価されているかといった分析が容易になる。