Hot Chips 26において、Oracleは次世代のSPARC M7プロセサを発表した。32コアという多数コアのチップで、富士通の34コアのSPARC64 XIfxと並んで、次世代SPARCは32コア+αという時代に突入した。
なお、OracleはM7プロセサ全体の発表と、キャッシュ階層だけの発表と計2件の発表を行い、後者は2人で分担して発表したので、合計3人が登壇した。

|

|

|
|
OracleのM7プロセサを発表するStephen Phillips氏 |
Oracle M7プロセサのキャッシュについての発表を行うRam Sivaramakrishnan氏(中央)とSumit Jairath氏(右) |
|
Oracleは2010年のSPARC T3から毎年、新しいプロセサを開発してきており、昨年のM6に続いて、今年はM7プロセサについての発表を行った。M6は28nmテクノロジを使い12個のS3コアと48MBのL3キャッシュを集積していたが、M7は32個のS4コアと64MBのL3キャッシュを集積するチップとなった。

|
|
Oracleは2010年から毎年新しいプロセサを開発してきている。(出典:この記事のすべての図は、Hot Chips 26における同社の2件の発表のスライドの抜粋である) |
次の図は、M7チップの写真と主要な諸元をまとめたものである。M7チップのサイズは発表されていないが、28nmから20nmプロセスへの移行でおおまかに2倍の素子が集積できるので、コアを2.7倍し、L3キャッシュを1.33倍という物量は、まあ、同じ程度のチップサイズに収まるのではないかと思われる。

|
|
M7プロセサは20nmプロセスで作られ、新世代のS4コアを32コアと64MBのL3キャッシュを搭載 |
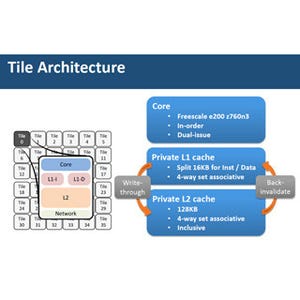
S4コアは、最大8スレッドのマルチスレッドで、同じ段数のパイプラインでクロック周波数を引き上げたと書かれている。クロック周波数は発表されなかったが、前世代のM6のクロックは3.6GHzであり、今回の発表資料でも4GHzを想定してバンド幅などが書かれていると思われる部分があるので、4GHzあたりがターゲットと推測される。
コア自体は2命令発行のOut-of-Order実行であり、この仕様だけみるとS3コアと同じである。次の図に書かれているように、あちこちで改良が加えられているが、基本的な部分は大きく変わっていないのではないかと思われる。

|
|
S4コアは最大8スレッドのマルチスレッドプロセサで、2命令発行のOoO実行 |
そして、このS4コア2個をペアにして256KBのL2 Dキャッシュを付け、これを2組まとめて256KBのL2 Iキャッシュを付けた4コアの集合をコアクラスタと呼んでいる。なお、L2 Dキャッシュは2ポート、L2 Iキャッシュは4ポートになっており、各コアは他のコアとのぶつかりなくL2キャッシュをアクセスできるようになっている。

|
|
4コアと256KBのL2Iキャッシュ、256KBのL2Dキャッシュ ×2をコアクラスタとする |
そして、このコアクラスタに8MBのL3キャッシュが付いている。後で詳しく説明するが、このL3キャッシュはコアクラスタごとに独立したように使うこともできるし、8クラスタの64MB全体を全コアで使うこともできるようになっている。この8個の8MBのL3キャッシュをOn-Chip Network(OCN)で結んでいる。また、OCNにはメモリコントローラとアクセラレータ、SMPのゲートウェイ、IOポートも接続されている。
このOCNであるが、リクエストを伝送するのはリングで、レスポンスを返すのはポイントツーポイントのネットワーク、そしてデータを伝送するのはメッシュと各種のトポロジのネットワークを組み合わせて使っている。このデータ伝送用のメッシュは0.5TB/sのバイセクションバンド幅を持っている。

|
|
4コアクラスタに8MBのL3キャッシュパーティションを付け、L3キャッシュパーティション間をオンチップネットワークで結ぶ |
この図に書かれているように、コアクラスタとL3キャッシュの間はコアクラスタからのReadが140GB/s、Writeが70GB/sで、メモリコントローラとの間のバンド幅はRead、Writeともに256GB/sで、これが2系統存在する。
メモリ系は4つのメモリコントローラで16チャネルを制御しており、CPUチップからは12.8~16Gbpsの高速リンクを出し、バッファチップを介してDIMMを接続する構造になっている。この構造はM6と同じであるが、M7ではDDR4をサポートし、さらにチャネル数を倍増したことにより、実測で160GB/sのメモリバンド幅を達成し、M6の2倍のバンド幅となっている。
PCI Expressは4リンクで75GB/s以上のバンド幅と書かれており、PCIe3.0 x8ではバンド幅が足りないのでx16になっていると考えられる。M6ではx8が2リンクであったので、この部分もかなり強化されている。

|
|
メモリはDDR4-2677を16チャネルサポート。PCIe3.0を4リンク持ち、75GB/s以上のIOバンド幅 |
結果として、次の図のように、M7は、M6の2.9倍から3.5倍の性能を達成している。コア数が2.5倍であるので、コアあたりの性能は1.16倍から1.4倍になっているという計算になる、

|
|
M7は、各種のベンチマークでM6に比べて2.9~3.5倍の性能 |