横浜で開催された「Cool Chips XVII」で、AlteraのDirk Seynhaeve氏がFPGAを使ったOpenCLで動かす並列処理プロセサについてのチュートリアルを行った。
GPUやXeon Phiをアクセラレータとして使う場合にはOpenCLによるプログラミングが使われる。しかし、これらのアクセラレータは32bitあるいは64bitの浮動小数点演算をメインに作られており、整数演算だけでビット数も少なくて良いという場合はオーバヘッドが大きい。そこで、専用のOpenCLアクセラレータを作って、より性能/電力の高いシステムを作る方法を説明するというのが、今回のチュートリアルの狙いである。

|
|
Cool Chips XVIIのチュートリアルで講義するAlteraのDirk Seynhaeve氏 |
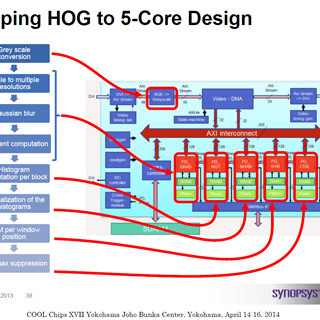
SynopsysやXilinxのアプローチは特定の処理に特化したプロセサを作り、それで性能や性能/電力を改善するというものであるが、より高い性能を実現しようとすると多数の並列処理パイプラインを持たせたり、複数コアを必要としたりして制御が複雑になる。
これに対して、Alteraのアプローチは、専用のプロセサを作る点は同じであるが、それをホストプロセサからOpenCLで書いたプログラムで動かすという点が異なっている。OpenCLは、GPUのような多数のスレッドで並列処理を行うためのプログラム言語であり、多数の処理パイプラインを並列に動作させる制御に適している。
次の図は簡単なプロセサのブロックダイヤであり、2つのレジスタの値を読み出し、乗算を行って結果をレジスタに書き戻す場合のデータの流れを示している。

|
|
簡単なCPUで2つのレジスタの積を計算し、結果をレジスタに格納する場合の動き |
メモリの101番地から読んだデータに42を掛け、それにメモリの100番地から読んだデータを足して、メモリの100番地に書き戻すという処理を行う場合には、プロセサの各部がそれぞれの命令を実行するようにデータやコントロールを転送する必要がある。
しかし、各命令の実行にあたって、本当にプロセサが行わなければならない処理だけを抜き出すと次の図のようになる。
特定の処理では、常に同じ命令列を処理するので、汎用プロセサのような命令のフェッチは必要ない。結果を使っていないALU演算やロード命令の処理も不要である。そして、結果を利用する命令に直接データを受け渡せば、レジスタファイルへの書き込み、読み出しも不要である。そして、この例には含まれていないが、実行されないようになっている命令も除いて良い。

|
|
各命令で、本当に動作する必要がある部分だけを抜き出した図。これをFPGAで実現してしまえば、性能/電力を大きく改善できる |
また、GPUでは常に32bitで演算を行うが、FPGAで実現する場合は、本当に必要なビット数分のロジックを作ればよい。メモリアクセスも電力を食い、速度も遅いDRAMをアクセスしなくても、本当に必要なだけの容量を持つローカルメモリを使えば、速度が速く、消費電力も少なくて済む。
これらの本当に必要な動作だけを実行する論理をFPGAで実現することにより、特に不動小数点演算を使わない場合は、GPUで実行するより大幅にコンパクトで消費電力も少ない実装が可能となる。そしてFPGAに多数個のプロセサを詰め込むことができる。

|
|
不要なオペレーションを省き、必要なだけのローカルメモリとデータ幅のロジックならコンパクトに作れ、FPGAに複数個のプロセサが入れられる |
そしてアクセラレータデバイス側で動かすDevice.clコードをAlteraのOpenCLコンパイラでコンパイルしてFPGAに入れてやれば、OpenCLのアクセラレータとして動作する。また、OpenCLのデバイスセレクト機能を使えば、次の図のようにGPUとFPGAのアクセラレータをホストで動く1つのOpenCLプログラムで使うこともできる。

|
|
デバイス側で動くDevice.clプログラムをAlteraのOpenCLコンパイラでコンパイルしてFPGAに入れてアクセラレータとして動作させる |
なお、AlteraのFPGAは外付けのDRAMメモリとしてDDR3、DDR4に加えてMicronのHMCもサポートしており、30GB/sという高いメモリバンド幅を利用できる。このため、高性能のアクセラレータプロセサを多数サポートできるようになっている。

|
|
AlteraのFPGAのDRAMメモリサポート |
このように、Synopsys、Xilinx、Alteraのアプローチは多少違うが、アプリケーションに特化した性能/電力に優れた解を、比較的少ない工数で、短期間に設計できる方法を提供している。
どの程度、省力化できるか、人手による設計と比べて設計の品質はどうかなどは、本当に使ってみないと分からないのであるが、開発期間の短縮には効果はありそうであり、検討に値する選択肢ではないかと思われる。