横浜で開催された「Cool Chips XVII」で、 XilinxのIgor Kostarnov氏がFPGAの高レベル合成ついてのチュートリアルを行った。
高い性能/電力を実現するためには専用のASICを開発するのが良いと分かっていても、開発工数が足りないし、専用チップを作る開発費も大変である。そのような場合には、このチュートリアルで説明されたVivado高レベル合成法を使って、FPGAで実現するという方法を考えてみるのは価値があると思われる。
|
|
|
Cool Chips XVIIのチュートリアルで講義するXilinxのIgor Kostarnov氏 |
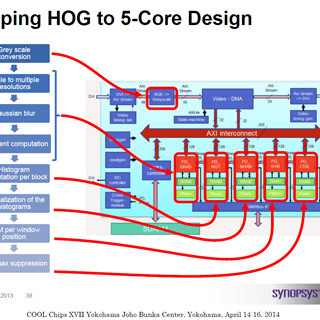
XilinxのVivadoは、C、C++やSystem Cで書いたアルゴリズムを高レベル合成(High Level Synthesis:HLS)でRTLに自動変換して、FPGAに書き込むことができるツールである。このため、ハードの知識をあまり持っていなくても、アルゴリズムが書ければ、FPGAを作ることができる。また、ベースとなるプロセサ、メモリ、入出力など各種の標準部品はIPとして提供されているので、自分で記述する必要はない。

|
|
Vivado HLSはC、C++、System Cのアルゴリズム記述から、VHDLあるいはVerilog RTLを自動合成する |
RTLレベルで記述されたモデルは、ハードウェアに近い詳細なモデルであるので、シミュレーションに時間がかかる。次の図の例では10フレームのビデオデータの処理をシミュレーションするのに約2日となっている。
これに対して、C言語で書かれたアルゴリズムをコンパイルして実行すれば、同じシミュレーションが10秒で終わり、12000倍速くでき、それだけ効率的にデバグが行える。そして、デバグが終わったら、RTLレベルのシミュレーションを1回行って、RTLレベルでも正しく動作することを確認すればよい。

|
|
10フレームのビデオデータの処理の場合、RTLレベルでシミュレーションを行うと2日程度かかるが、C言語レベルなら10秒でシミュレーションできる |
他の例では、Verilogで12日かかった設計が、Cで書いてVivadoでRTLを作る方法を使うと1日で設計ができ、FPGA化した場合の使用メモリ、レジスタ、LUT数も、人手による設計より少なくて済んだという。
Cソースの1つの関数がRTLのブロックに対応し、次の図のコントロール挙動の(0)が始まる。そして、forループの部分が(1)で、ループを示す矢印がついている。さらに、forループの終わりから関数の最後までが(2)という制御構造と認識される。
そして、それぞれの文の操作がOperationの部分に抽出されており、両方を合わせてFPGAに入れるRTLを生成している。

|
|
関数の開始、終了と、内部のループという制御構造を抜き出し、それぞれの文を演算操作に置き換える。そして、右端の制御とデータパスの挙動を作る |
次の図に示すように、関数の引数が入出力ポートとなる。なお、クロックとリセット、回路の動作のStartと、回路の状態を示すIdleとDoneもポートとして付加されている。

|
|
関数がRTLに対応し、関数の入出力が入出力ポートに変換される |
そして、信号の入出力ポートにはAXI4バスインタフェースマクロが接続される。

|
|
入出力のAXI4のポートが付けられる |
次の図は、a[i]を次々と足しこむという簡単なループの例であるが、通常は上の図のようにアダーとレジスタのループで実現されるが、ループを4回アンロールして変換すると下の図のようなRTLを作ることもできるという。
ただし、この実装はあまり良いものではない。2入力アダー2個で、それぞれa(0)とa(1)、a(2)とa(3)を足し、それらを第3のアダーで足してa(0)~a(3)の和を作り、第4のアダーで第3のアダーの出力とレジスタからの値bを足すという回路にすれば、a入力からレジスタまでのアダー通過段数は3段で、レジスタ出力のbからレジスタ入力まではアダー1段の通過となる。この構成とすれば、部品数は同じで、アダー通過段数が少ない分、高速のクロックで動作できる。この図の回路は、ハードに詳しくないソフト屋さんが作ったという感じである。

|
|
C言語のループはハードウェアのループに変換される。下の図のように、ループアンロールした回路を作ることもできる |
それはともかく、CやC++でアルゴリズムを書いて、高速でシミュレーションを行ってデバグを行い、完成したらRTLを自動合成してFPGAが作れるというのは設計の省力化と開発期間の短縮には貢献しそうである。