富士通研究所は1月15日、暗号化された文字列データを復号せず暗号化したまま検索することができる秘匿検索技術を開発したと発表した。
同社は昨年8月、データを暗号化したまま演算処理を行う準同型暗号の高速化技術を開発したことを発表しているが、今回の秘匿検索技術は、これを応用したもの。
今回開発した技術は、暗号化した検索文字列と暗号化されたデータ成分の1つずづずらしながら、同じ並びのデータが存在するかどうかを判定するもの。そのため、検索対象のデータと検索する文字列は、同じ暗号方式を利用することが前提となる。

|
文字列検索の仕組み |
暗号化したまま統計処理などの演算が行える準同型暗号の技術をベースに、一回の処理で複数の暗号演算を同時に行えるように改良することで、文字列全体に含まれる検索キーワードの一致判定を一括して行うことができる。検索スピードは、16,000文字の秘匿検索が1秒以内で行えるという。

|
開発した秘匿検索技術の特徴 |
開発した技術は、暗号化されたデータと検索キーワードとの一致判定を暗号化したまま行えるため、検索キーワードを事前に登録せずに、任意のキーワードで検索することが可能。また、検索結果出力も暗号化したままにできる。
ただ課題もある。処理時間は扱う文字列に比例して大きくなるため、実用化に向けては、不一致文字数計算の繰り返しによる検索時間の増大が課題として挙げられる。そこで同社は、今後、不一致文字数計算の肝となる内積計算に着目し、高速化していくという。具体的には、多項式乗算の性質を利用し、すべての内積計算を同時に実行するという。

|
実用化に向けた課題 |

|
富士通研究所 セキュアコンピューティング研究部 主管研究員 小暮淳氏 |
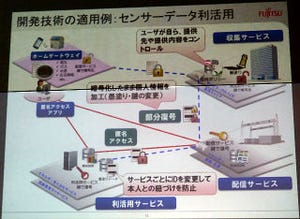
富士通研究所 セキュアコンピューティング研究部 主管研究員 小暮淳氏によれば、適用分野としては、医療情報やゲノム情報などの生化学・医療分野のほか、成績情報などの教育分野を想定しているという。 例えば、この技術をDNAに含まれる塩基配列の検索に応用することで、患者のDNA情報を暗号化で秘匿したまま、特定の配列パターンが含まれているかどうかを調べることが可能になり、新薬の研究開発の効率化が期待できる。特に病歴などはプライバシーに深く関わるデータであり、今回の技術を使うことで安全に検索を行うことができる。これら生化学・医療分野以外にも、例えば複数の教育機関が合同で成績情報を分析するなど、プライバシー性の高いデータの検索をより安全に行うことが可能となる。

|
適用例(塩基パターンと病気の関係を調べる) |
同社は今後、2015年の実用化を目指して実証実験などを進めていくという。