NECは12月3日、都内で同社の研究開発に関する説明会を開催し、今後の同社の研究開発の方向性などを示した。
|
|
|
NEC執行役員の江村克己氏 |
同社執行役員の江村克己氏は、「2050年には世界の人口は新興国を中心に90億人に増加し、経済規模は4倍に拡大することが見込まれているが、地球上の資源は有限であり、それを効率的に活用していく必要があり、そのための"新しい社会インフラ"の構築が重要になる」とする。
こうしたニーズを受けて同社では現在、ICTの活用を通して、社会インフラの高度化を支えることを目指したビジネスを中心に据えており、研究開発にもそうした対応が求められるようになってきているという。
そうした動きの中、同社が近年、注力しているのが、「パブリックセーフティ」「ビッグデータ」「SDN」「スマートエネルギー」の4つのソリューションであり、こうした社会の動きを意識した結果、研究開発体制にも変化が生じ、現在では、研究開発の時点から顧客とどういった課題を解決していくかを話し合い、その価値の軸でNo1/Only1の技術を開発していく方向に向かっているという。ただし、1つの技術を新たに開発しただけでは、そうした顧客ニーズの解決は基本的にはできないことから、社内外の技術を組み合わせ、実際のソリューションとして構築して、実証試験などを行うことまで求められるようになってきているとする。

|
|
NECが近縁注力している4つのソリューション |
現在、同社が社会インフラの高度化に向けて取り組んでいるのは「データ収集」「データアナリティクス」「データ分析基盤」「ネットワーキング」「セキュリティ」「サービス構築」「エネルギー」の7つの領域。

|
|
4つのソリューションに対応するための7つの注力領域 |
中でもデータの分析基盤としては、同社が長年培ってきたベクトル型スーパーコンピュータ(スパコン)をデータの解析に活用することで、より高速にリーズナブルにリアルタイム処理を提供していけるとする。
とはいえベクトル型スパコンだけですべてのビッグデータを処理できるかというとそうではないため、「ベクトル型スパコンと汎用サーバ(スカラ)型スパコンのハイブリッド型が将来のHPC/データセンターの姿になる。基本的には顧客が行いたい処理に対し、コスト効率を最大限に発揮できる構成をソリューションとして提供していく」と、ベクトル型スパコンには一定のこだわりを見せつつも、顧客のニーズ優先でデータ処理のハードウェアを提供していくことを強調する。

|

|
|
NECが培ってきたベクトル型スパコンの歴史とそこで生み出された技術。汎用サーバとそれらを組み合わせることで、それぞれの顧客のニーズに応じたデータのリアルタイム処理が可能になる |
|
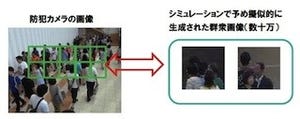
こうしたハードウェアとソフトウェアを組み合わせたソリューションとしての観点では、同日同社は「リアルタイム処理を実現する並列演算のソフトウェア技術」を開発したことを発表している。
同技術は、Xeon PhiのようなコプロセッサやGPUコンピューティングといったアクセラレータが持つ無数のコアをリニアに活用することで、効率的にアプリケーションプログラムの効率的な並列化と、その処理を各コアに均一に分散させることを可能とするもの。
公開されたデモではXeon Phi(Knight Corner)を用いて、空いているコアを動的に活用して処理を行うことで、汎用プロセッサコアでは不可能といえるレベルの高速な処理を実現している様子が示された。また、デモではXeon Phiを用いていたが、研究開発ではGPU対応も進めているとのこと。Xeon Phiを優先しているのは、C/C++で書かれた既存アプリケーションをCUDAなどを用いずに、そのまま並列演算に持っていきやすいためだという。

|
|
左のモニタがXeon Phiを用いている場合で、右が汎用サーバのプロセッサのみで顔認識処理をしているところ。Xeon Phiを用いていると1秒以下で顔認識を実現していることが分かるが、汎用サーバのプロセッサ単体では10秒(実際にはこれ以上)かかっていることがわかる |
また、同技術の実用化は2015年ころを目指しているとするが、その後、2016年にはサーバ単体ではなくネットワーク越しに複数のコプロセッサのコアを自由に活用できるようにするところまで発展させる予定としており、その先に大規模な社会インフラの高度化の実現を目指すとしている。
なお、アクセラレータとしては、コプロセッサでもGPUでもFPGAでも実は何でも良く、元のコードをコンパイルできるかどうかの問題となると同社では説明しているほか、サーバ間での通信時にHPC分野で起こるような遅延などは現状のビッグデータニーズでは基本的に問題になりづらいとの見方を示している。

|

|

|
|
ビッグデータのリアルタイム処理を実現するための技術の概要。スケジューラによりリアルタイムで各コアの空き具合を監視しており、例えば処理を30コアで開始し、途中でさらに10コア空いた、という状態であっても、柔軟にその10コアを加えて演算処理を実行することなども可能だという |
||