エクサスケールの実現に向け、日本が取るべき道とは?

|
|
日本のエクサスケールスパコンの開発に向け、第3の道を説く松岡教授 |
エクサへの道であるが、NVIDIAのGPUのようなアクセラレータを日本が開発するのは容易ではない。NVIDIAはハードウェアだけでなく、CUDAやCUDAライブラリの開発に大きなリソースをつぎ込んでおり、これをキャッチアップすることは難しい。
IntelのXeon Phiのようなメニーコアチップを作るのも、京コンピュータに使ったSPARC64の低電力小規模コアはなく、やるとすればARMを使うしかない。そうなると、高性能のSPARC64コアとのヘテロ構成ではプロセサの命令が違うことになってしまう。従って、Xeon Phiを追いかける道も現実的ではない。
しかし、日本には第3の道があると松岡教授は説く。
東工大はGPUスパコンのハードで先端を走るだけでなく、青木教授らを中心とするアプリケーションのチームと、松岡教授を中心とするソフトウェアグループの層が厚く、かつ共同研究でお互いに深く連携しているのが強みである。
青木教授のグループは、気象庁が開発中の次世代気象予測ソフトであるASUCAのGPU対応を行って、大幅な性能向上が行えることを示したり、金属の結晶状態のシミュレーションで2011年のゴードンベル賞を受賞するなどの成果を上げている。
東工大のグループは、このように多くの実アプリケーションを見てきた経験から、やはり、最後はメモリアクセスが実効性能を決めると言う。
CPU/GPU内部の演算はそれほどエネルギーは消費しないが、チップ外のメモリをアクセスするには大きなエネルギーを必要とするし、他のGPUに接続されているメモリにアクセスするにはさらに大きなエネルギーを必要とする。また、アクセスするメモリが遠くなるに従って、一般的にはメモリバンド幅が小さくなり、性能が制約される。
この問題はずっと以前から認識されており、High Performance Linpack(HPL)でもブロッキングという手法でメモリアクセスを減らして性能を上げている。
カリフォルニア大学のバークレイ校のDemmel教授のグループは、メモリアクセス回数や通信回数を減らすCommunication Avoidanceという手法を研究しており、LINPACKのような線形代数問題に対して、通信回数や必要バンド幅の下限を改善する計算法をいくつも提案している。また、GMRESなどの反復解法や、疎行列でも通信やメモリアクセス数の下限を改善する計算法を提案している。
松岡教授のチームはCommunication Avoidanceの考え方を適用して通信量を減らす研究を行っており、気象計算や多くのアプリに使われているステンシル計算の性能を改善する論文を2013年5月の学会で発表している。Naïveと書かれた通常のアルゴリズムでは、各次元の格子数が760を超えるあたりでGPUの3GBのメモリにデータが収まらなくなり、PCI Express経由で他のメモリをアクセスするために、急激に性能が下がっている。これに対して、直近のアルゴリズム改善では、この2倍の格子数までほぼフラットで、2160でも70%程度の性能を保っている。

|
|
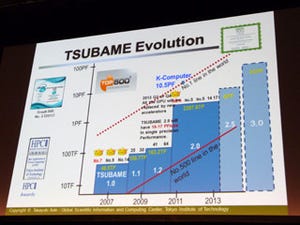
気象計算などに使われる7点ステンシル計算の性能。横軸は各次元の格子数、縦軸はGFlops |
エクサの時代に向けては、半導体の微細化で演算性能を上げることは可能であるが、メモリバンド幅や通信バンド幅を演算性能に見合って増加させることは望み薄である。また、計算ノード数が100万のオーダになると予想され、それらの計算ノード間の通信を減らすことが重要になる。このため、Communication Avoidingなアルゴリズムの開発が非常に重要と松岡教授は言う。
しかし、Communication Avoidanceの理論では、例えば、行列積の場合のメモリアクセス量の下限は、Flops/SQRT(M)に比例する。ここでMはメモリ量である。つまり、メモリアクセスも含めた通信量を減らすためには、大きなローカルメモリが必要である。
松岡教授は、汎用のメニーコアCPUチップに大容量のメモリチップを、TSV技術を使って10万ピンレベルで直結し、高メモリバンド幅、かつ多数の複雑なメモリトランザクションを並列に実行するのに適したプロセサを日本は作るべき、と主張する。
LINPACKでの1Exa実現よりも実際の科学技術計算の効率重視を
このプロセサは、Flops値では、NVIDIAのGPUや、IntelのXeon Phiメニーコアには勝てないが、大規模な科学技術計算の実行では高い性能を発揮するという点でこれらのプロセサに対して優位に立てる。従って、LINPACK性能が1 Exa Flops(10の18乗浮動小数点演算/秒)にこだわるべきではなく、エクサスケールの科学技術計算を効率よく実行できるスパコンという目標とすべきであるという。
また、このプロセサはBig Data処理にも威力を発揮する。スパコンは重要であるが、売れる台数が少ない。しかし、Big Dataは科学技術計算用のスパコンよりも用途の幅が広く、より大きなマーケットがある。そうなれば、コンピュータメーカーとしてビジネス的な採算に乗せられる可能性が出てくるという。
また、京スパコンのときの1京Flopsのように、やみくもにエクサフロップスのベンチマーク性能を追求するのではなく、サイエンスドリブンに様々な重要なアプリケーションにおいて高い実効性能を容易に出せることが重要、と指摘する。
松岡教授のチームは、理化学研究所の計算科学研究機構と合同でポスト京のアプリケーションのFS(フィージビリティ・スタディ)行っており、その成果を本年度「計算科学ロードマップ白書」として出版する予定である。その中では、アプリケーションから見た次世代スパコンの要件が明らかにされるとのことである。
京スパコンやその後継の富士通のFX10スパコンは、プロセサは米国に負けていないが、1筐体に96計算ノードしか入っていない。これに対して、IBMのBG/Qは1024ノードを1筐体に収容しており、密度が圧倒的に違う。筐体の数が多ければ、それだけインタコネクトのケーブルの本数や長さが増え、消費電力も多くなり、冷却エネルギーが多く必要となる。そして、3000平方メートルの巨大コンピュータルームが必要になる。
京スパコンでは膨大な物量をつぎ込んでペタを実現したが、エクサの時代にはこれは通用せず、高密度、小型化が必須であるという。
また、スパコンの技術というとプロセサが注目されるが、ノード間を接続するインタコネクト、ファイルシステム、冷却、そして、運用技術を含めた全体的なエンジニアリングの最適化が重要であるという。そして、Big Dataへの展開と合わせて、全体として米国や中国に勝てると信じられる戦略をたて、これを推進していくことが日本の進むべき道であるという。