理化学研究所(理研)は、情報通信研究機構、脳情報通信融合研究センター、国立精神・神経医療研究センターとの共同研究により、fMRI実験で計測された脳活動を意思決定の脳計算モデルで解析することで、ヒトの脳が「他人の心のシミュレーションによる学習」と「他人の行動観察による学習」を統合して、他人の価値観を学ぶことを科学的に解明したと発表した。
成果は、理研 脳科学総合研究センター 理論統合脳科学研究チームの中原裕之チームリーダー、鈴木真介客員研究員らの研究グループによるもの。研究の詳細な内容は、日本時間6月21日付けで米科学雑誌「Neuron」オンライン版に掲載された。
他人の心を理解して行動することは、ヒトの社会生活上の根本的な能力だ。一方で、ヒトは「他人の心」を直接見ることはできない。では、ヒトはどうやって他者の心を理解するのだろうか?
それには古くからさまざまな議論があり、有力な説の1つは、「シミュレーション説」だ。「自分の心のプロセスを基にして、他人の心のプロセスをあたかも自分のプロセスとして実現する」というものである。
他方、「行動パターン説」もあり「シミュレーションは不必要で、他人が何にどう反応するかのパターンを学習して、他人の目に見える行動を当てている」も捨てがたいとして支持されてきた。
これらの説のどちらが正しいかはもちろん、ヒトの脳で実際にどう実現されているのかもわかっていない。それは、ヒトの心が非常に複雑な概念であり、科学的な実験で検証することが難しかったからだ。
科学実験では、対象を明確に定義することが不可欠である。特に複雑な働きから成り立つ脳の機能を理解には、そのプロセス(脳の情報処理のプロセス)を数理的な計算モデルで記述することで、その機能を定量的に検証することが重要だ。
今回の研究では、特に、報酬予測という価値判断の意思決定に焦点を当てた。これは、今までのヒト及び動物の脳研究の蓄積から、報酬量の予測に基づく行動選択(価値判断に基づく意思決定)を繰り返し行う中で、予測した報酬量と実際の報酬量の違いである「報酬予測誤差」を手掛かりに、ヒトが適切な報酬予測を学習することを根拠にしている。
しかも、この報酬予測誤差学習の脳計算モデルが定式化されており、理論と実験を組み合わせる今回の研究に適しているという点も理由の1つだ。これを基にして、「ヒトはどうやって他人の価値判断を学習そして予測するのか」を明らかにするために研究が進められた。
今回の研究では、さらに、計測したヒトの脳活動を、「モデル化解析」と呼ばれるデータ解析手法を用いて解析した。ある仮説に基づく脳計算モデルは、その仮説に基づいた実際の行動の予言と共に、仮説から脳の働き(脳の計算、情報処理ともいえる)も予言する。従って、もし仮説(脳計算モデル)が、適切であれば、行動データによく対応し、さらに挙動に対応する十分な脳活動を示すはずだ。
モデル化解析では、複数の仮説を、それぞれの脳計算モデルがどれだけ行動データに対応するか調べることで、行動レベルの適切な仮説を選ぶと同時に、その働きに対応する脳活動を調べる。これにより、複雑な脳の働きを、定量的に把握すると同時に、行動と脳情報処理の両方の検証を同時に行う。
今回の研究では、30名を超える被験者がfMRI装置に入り、2つの実験課題が行われた。1つは、今までの知見を利用した、本人が自分のために報酬予測を行う「報酬学習課題」(画像1)だ。
「報酬学習課題」では、被験者は「2つの図形のどちらかを選び、その選択が正しければ報酬を得る」という試行を繰り返し行った(正しい図形は各試行で確率的に決まる)。この課題では、報酬予測誤差学習の脳計算モデルが被験者の心の中のプロセスに対応する。
そして、もう1つの新たな課題は「他者予測課題(報酬学習課題を遂行中のほか人の行動を予測する課題)」(画像2)だ。この時、シミュレーション説に基づけば、他人の心の中の報酬予測誤差学習のプロセスを、「(被験者本人の報酬予測誤差学習のプロセスを利用して)他人のプロセスを自分の脳内で再現する」はずである。この脳計算モデルは、最初の課題で用いた報酬予測誤差学習の脳計算モデルを援用することで実現可能だ。
一方で、行動パターン説の脳計算モデルは新たに構築する必要があった。研究グループは「予測した他人の選択と、実際のほか人の選択を比べる行動予測誤差を用いて、他人の価値判断を学習する」という、行動パターン説に対応する脳計算モデルの構築に成功したのである。これにより2つの説を、脳計算モデルに基づいて定量的に評価することが可能になった。
画像1は、報酬学習課題。被験者は「2つの図形のどちらかを選び、その後、選んだ図形が「正解」であれば報酬を得る」という試行を繰り返し行う。被験者が選択した図形は「確認」の時に「灰色枠」で示され、その被験者の選んだ図形が、「結果」の時に中央に出る図形と一致していれば、被験者は報酬を得ることになる。高報酬を得るためには、被験者は試行を重ねていく中で、どちらの図形が正解になる確率が高いのか(価値判断)を学習していく必要があるというわけだ。
画像2は、他者予測課題。被験者は「報酬学習課題を遂行中の他人の行動」を予測するという内容で、予測が的中すれば報酬がもらえる。(「結果」で、他者の選択は「赤枠」で示され、被験者の選択(「灰色枠」)がこの「赤枠」と一致している時に、被験者は報酬をもらえる)仕組みだ。

|

|
|
画像1(左)が報酬学習課題で、画像2が他者予測課題(画像中の課題は、簡単に理解できるように、オリジナルの実験課題を簡略化して示している) |
|
最初に「報酬学習課題」のデータの解析が行われた。第1に、行動データと報酬予測誤差学習の脳計算モデルの振る舞いを比較することで、確かに、被験者が報酬予測誤差を利用して報酬予測を学習していることが確認された次第だ。
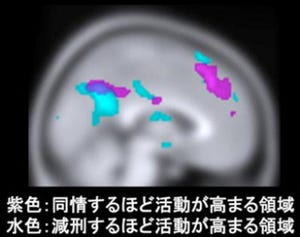
次に、脳計算モデルの挙動を基にして、対応する脳活動データを調べることで、「報酬予測誤差に基づく学習」そして「価値判断に基づく意思決定」の両方が、前頭葉の腹内側部で処理される(画像4・青い領域)ことが確かめられた。
その上で「他者予測課題」での行動データを詳細に解析。これから、シミュレーション説、そして行動パターン説の個々の脳計算モデルよりも、両方の計算モデルを統合した脳計算モデルの挙動が、行動データと最も対応することが発見された。
この結果は、どちらか一方の説だけでは正しくないことを示している。むしろ、2つの説を統合させることが正しい、つまり、ヒトは、シミュレーションによる学習と相手の行動パターンによる学習を統合して用いることで、他者の価値判断を学んでいることを示しているのだ。
さらに、脳活動データをモデル化解析手法で調べることで、2つの学習に対応する脳活動、すなわち、2つの学習それぞれの具体的な情報処理が脳に存在することが見出された。
さらに、その脳活動は、社会性などに関連すると考えられている前頭葉の内側部(画像3)の別々の領域で行われていることが発見された(画像4)。シミュレーション学習の脳領域(画像3・赤い領域)が、確かに「報酬学習課題」で被験者が自分自身のために行っていた報酬予測の学習と価値判断の選択のための脳領域(画像4・青い領域)と重なることが発見された(画像4・紫の領域)。
これは、自分のプロセスを基に他人のプロセスをシミュレーションしていることを脳活動として実証している。行動パターン学習は別領域(画像4・緑の領域)で処理されていた。
ヒトの脳は、シミュレーションを通じて他人の価値観を学習するだけでなく、他人の行動観察に応じて起きる前頭葉の別領域の活動により、その学習をたえず補正することで、他人の価値観をより精緻に学習していることがわかった。
画像3は、脳の中央部を側面から見た図(左側が顔の側に対応し、右側が頭の後ろ側に対応)。オレンジの領域が前頭葉。
画像4は、報酬学習課題を遂行中の脳活動(青)と他者予測課題を遂行中の脳活動(赤、緑)。青い領域は自分自身の報酬予測誤差学習と価値判断による行動選択に関連する脳活動を示している。
赤は他者の報酬予測誤差学習をシミュレーションするのに関連する脳活動(シミュレーションした、他者の「報酬予測誤差」を処理する脳活動)。緑は、他者の行動パターン学習に関連する脳活動(他者の「行動予測誤差」を処理する脳活動)。

|

|
|
画像3(左)は、脳を側面から見た断面図で、画像4は今回の研究の主な脳活動(画像3は、BrainTutor(free software)の図から掲載) |
|
そもそもヒトは多様な価値観を持っている。今回の研究で明らかにされた、シミュレーション学習と行動パターン学習を統合するヒト脳による他人の価値判断の学習は、他人の多様な価値観への対処に役立つと思われるという。
自分と似た価値観を持つ他人について学ぶには、シミュレーション学習が主な役割を担うと思われる。一方で、自分と異なる価値観を持つ他人には、シミュレーション学習だけでは対処しきれない可能性が高く、行動パターン学習との統合学習が特に効力を持つと考えられるとした。
脳科学は現在急速に発展しており、特に近年は「ヒトの高度な社会知性を支える脳の仕組み」の解明へと広がりを見せている。今回の研究では、社会知性の根幹にある「他人の心を理解する能力」について、脳の仕組みの一端が明らかになった形だ。
この成果は、ヒトの社会知性の神経的基盤の解明に貢献し、将来、対人関係に支障がある精神疾患の究明、多様な価値観を学び対処する社会性を持つコンピュータやロボットの開発への貢献が期待されるとした。
また、今回の研究のアプローチ、脳計算モデルあるいはモデル化解析手法を用いた社会知性の脳機能理解の研究は、今後、大きな展開が期待されており、諸処の社会科学で扱われる政治・経済・社会の問題にヒト脳機能理解から迫る神経経済学や社会脳科学、ひいては統合人間脳科学に貢献すると、研究グループはコメントしている。