スタンフォード大学で8月22日から24日にかけて開催されたHot Chips 22で発表のトリを飾ったのがAMDのBrad Burgess氏の「Bobcat」の発表である。

|
|
Bobcatコアの発表を行うチーフアーキテクトのBurgess氏 |
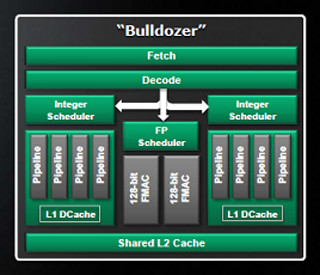
「Bulldozer」は土木工事などの使われるご存じのブルドーザーである。Bobcatは大型のネコ科の猛獣であるが、それ以外に、水道管の取り換え工事などに使われている小型のブルドーザーという意味がある。AMDの命名は後者で、Bulldozerはサーバからデスクトップの範囲をカバーし、BobcatはノートPCやタブレットなどをカバーすると位置づけられている。

|
|
AMDのBulldozerとBobcatコアの位置づけ |
Bobcatの設計ターゲットの第一は電力、チップ面積が小さいこと、2番目が高い性能であるが、その次にカスタム設計のメモリなどの種類数を少なくして、プロセサコアの大部分を論理合成で作れるようにすること、そしてプロセスが変わっても容易に移行できることが挙げられている。

|
|
Bobcatの設計ターゲット |
Bobcatコアを使用する最初の製品である「Ontario」はTSMCの40nmプロセスを使うと見られているが、関係の深いGLOBALFOUNDRIESのプロセスへの移行も視野に入っていると思われる。

|
|
Bobcatのブロック図 |
ブロック図にみられるように、Bobcatは32KB 2wayセットアソシアティブの命令キャッシュからフェッチした命令を2命令ずつデコードする2命令並列実行のマイクロプロセサである。このデコーダは89%のx86命令は1対1でマイクロOPに変換し、10%のx86命令は2マイクロOPに変換する。そして、より複雑な1%以下のx86命令はuCodeと書かれたマイクロコードROMを使ってマイクロOPに変換している。
整数の実行エンジンでは、各命令に対してレジスタリネームを行って演算用とメモリドレス計算用のスケジューラに命令を送り込む。そして、整数演算を行うALUが2パイプとロード命令用のアドレス計算を行うLAGU、ストア命令用のアドレス計算を行うSAGUがあり、瞬間風速的にはこれらの4つ計算を並列に実行できる。なお、乗算を行うMulパイプを持っているのは一方のALU側だけであるので、乗算は1演算/サイクルのスループットと考えられる。
一方、FP(Floating Point)側も2命令をデコード、リネームして発行できる機構と2つの実行ユニットを持っている。MMX ALU演算とFP Logical命令はどちらのユニットでも処理が可能であるが、左側の実行ユニットはFPのAddとIntMul、右側の実行ユニットはFPのMulとSt Convというように機能を分担している。
Out-of-Order実行プロセサでは、各実行命令の結果レジスタは、次の図の右側の赤く書いた投機実行結果レジスタファイルのレジスタにリネームされ、命令がコミットする時点で実行結果を左側の青いアーキテクチャレジスタファイルにコピーするという方式をとるプロセサが多い。このコピーをプログラムに命令が書かれた順に行えば、演算がOut-of-Orderに行われても、アーキテクチャ状態の変化はプログラム順のIn-Orderになる。また、分岐予測がはずれた場合などは、投機実行結果を入れるレジスタファイルをクリアすれば、アーキテクチャ状態は、予測がはずれた条件分岐命令の直前の状態に戻れる。

|
|
一般的なOut-of-Order実行の機構 |
これに対してBobcatの実行ユニットでは、投機実行結果を入れるレジスタファイルは持たず、1つの大きなレジスタファイルにすべての結果を入れ、タグの部分でそれぞれのエントリが何番のアーキテクチャレジスタに対応しているかなどの情報を持ち、アーキテクチャ状態と投機実行結果の区別を行っている。

|
|
BobcatのOut-of-Order実行の機構 |
このため、命令がコミットすると、その命令の実行結果を保持している共用レジスタファイルのエントリがその命令の結果を格納するアーキテクチャレジスタとなる。というように各アーキテクチャレジスタが共用レジスタファイルのどのエントリに対応しているかを示すタグ部分を次々と書き換えていく。このため、アーキテクチャレジスタにあるオペランドの読み出しにも変換表を引く必要があり、また、分岐予測はずれなどの場合にはタグを元の状態に戻すためには複雑な動作が必要である。
しかし、このようなタグの操作はビット数が少ない。したがって、命令コミット時に64ビットのデータを投機実行用のレジスタファイルから読み出し、アーキテクチャレジスタファイルに書き込むのに必要なエネルギーと比べると、ずっと少ないエネルギーで済む。つまり、Bobcatでは設計の複雑さは増加するが、低電力を優先するという選択を行っている。
整数ユニットのLAGU、SAGUで計算されたメモリアドレスはLdSt(Load Store)ユニットに送られ、DTLBでアドレス変換され32KB 8wayセットアソシアティブの1次データキャッシュをアクセスする。制御構造を簡単にするため、1次データキャッシュはライトスルー方式として、1次キャッシュへの書き込みと同時に2次キャッシュにも同じデータを書き込むプロセサも多くみられるが、Bobcatでは2次キャッシュへの書き込み回数を減らすために、1次キャッシュをライトバック方式にしている。
ここでも、設計の複雑さという犠牲を払って低電力となるマイクロアーキテクチャを選択している。また、1次キャッシュではDTLBとキャッシュのデータアレイを並列にアクセスしてスピードを優先する設計のプロセサが多いが、Bobcatでは、まず、DTLBを引いてアクセスを必要とするWayを知り、それに基づいてキャッシュのデータアレイの1つのWayだけをアクセスするという方法を採っている。この方法では1次キャッシュのアクセスが1サイクル長くなるが、ここでも性能よりも低電力化を優先している。
そして、1次キャッシュをミスするとバスユニットを経由して512KB 16wayセットアソシアティブの2次キャッシュをアクセスする。この部分はクロックをCPUコアの1/2として省電力化している。
さらに、Bobcatコア全体で、動作を必要としない部分のクロックを細かく制御するファイングレインのクロックゲートやリークの少ない高Vtトランジスタの使用率の増加、プロセサコアのパワーゲートなどの省電力手法を組み合わせ、低電力化を行っている。

|
|
Bobcatのパイプライン図 |
Bobcatのパイプラインは簡単な整数命令の場合で12ステージで、Out-of-Order実行を行うx86アーキテクチャのプロセサとしては短めであると言える。したがって、推測であるが、兄貴分のBulldozerのように高クロックを狙うのではなく、比較的遅めのクロックで、低電力を狙う設計であると思われる。

|
|
Bobcatコアのフロアプラン |
そして、Bobcatコアのフロアプランであるが、キャッシュやTLBなどのSRAM部分を除くと地図のように複雑に入り組んだ形状となっている。カスタムレイアウトを行うプロセサではこのようにはならず、BobcatコアはCADで自動配置、配線を行って作られたことを示している。最初にあげたプロセスが変わっても容易に移行できるという設計目標を実現するため、ロジックは論理合成で作り、そして自動配置配線を行うというASIC風の設計メソドロジを使っていると考えられる。
Bobcatコアのクロックや性能は明らかにされていないが、Out-of-Order実行であることから、サイクルあたりの性能はIn-Order実行のIntelのAtomよりは2~3割程度高いと思われる。クロックもAtom並みのクロックの実現はできると思われるので、Atomを上回る性能が期待される。
また、各種の低電力化の工夫を採用しており、かなり小さなコア電力となっていると思われる。加えてASIC設計メソドロジの採用で異なるプロセスへの移行性が高く、AMDは言及していないが、SoCのコア化の点でも機動性の高いコアであると考えられる。
なお、発表ではBobcatという開発コードネームは小型のBulldozerという意味で名付けられたと説明されたが、噂によると、AMDの次のハイエンドコアは「Steam Roller」(道路のアスファルトを平らにする)であるが、下位のコアは「Jaguar」と言われ、ネコ科の猛獣シリーズの命名という解釈もある。