三菱電機は3月25日、機密情報を含むファイルを自動検出するソフトウェアを開発したことを発表した。

|
|
三菱電機 情報技術総合研究所 ビジネスプラットフォーム技術部 部長の撫中達司氏 |
新製品の特長は、検出精度の高さと、検出条件の設定作業が簡略化された点。あらかじめ登録した"機密文書で頻繁に使われる文字列"とのパターン照合を行う「キーワード検索」と、機密文書/非機密文書で使われる文字列を自動検出する「学習型フィルター」を組み合わせることで、管理作業の負担を軽減しつつ、検出漏れや過剰検出の頻度を減らしている。
三菱電機 情報技術総合研究所 ビジネスプラットフォーム技術部 部長の撫中達司氏は、機密文書検出ソフトウェアの現状を振り返り、「従来の機密文書検出ソフトウェアでは、フィンガープリントを応用した方法か、キーワード検索のいずれかの方法が用いられているが、前者は、事前登録された機密文書に完全一致もしくは部分一致する文書しか検出できないという欠点があり、後者は、精度を高めるのキーワード選定作業が非常に難しく煩雑という問題を抱えている」と指摘。そのうえで、今回発表されたソフトウェアが、双方の課題を同時に解決できることを説明した。
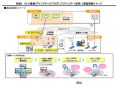
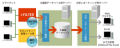
検出処理のイメージは以下のとおり。

|
|
検出イメージ |
機密文書/非機密文書として登録したファイルから統計的特徴を抽出し、それらの情報(キーワードや登場頻度など)をリポジトリに登録。その内容と対象のファイルを付き合わせ、機密/非機密の判定を行っている。なお、ある程度の精度を確保するために必要な登録ファイル(機密文書/非機密文書)数の目安は「500ファイル程度」(三菱電機 情報技術総合研究所 ビジネスプラットフォーム技術部 ビジネスデータ基盤技術チーム チームリーダーの郡光則氏)という。

|
|
検出の仕組み |
三菱電機では、1万3000のファイルを登録して1万4000のファイルを判定させた結果、検出漏れの評価で99.9%、過剰検出の評価で98.7%という精度が確認できたとしている。
同社では、この技術を2009年度内に事業化する考えで、メールに含まれる機密情報を検知するシステムや、PC/サーバ内の機密文書ファイルを検出システムの開発に応用していく予定だ。