筆者は、数年ぐらい前からテキストファイルにUTF-8を使っている。1つには、Shift-JIS文字よりUnicode文字のほうが利用できる文字種が多い点がある。たとえば、絵文字やコピーライトマーク、アクセント付き文字などである。テキストファイルのエンコードは、作成側と受け取る側の合意事項でしかないため、長らく日本語はシフトJISが標準的だったが、今では多くのソフトウェアがUTF-8の表示や編集に対応している。Windows 10で標準のメモ帳やエクスプローラーのプレビューなどが、UTF-8などシフトJIS以外の文字エンコードに対応した。
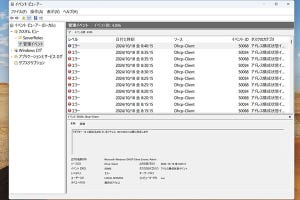
残念なことに、Windowsの全文検索機能(Windows Search)は、UTF-8にまともに対応していない。ファイルの先頭にByte Order Mark(以下BOMと表記)がないと、UTF-8と認識しないため、日本語の検索ができないのである。シフトJISやBOMがつくUTF-16LE(Little Endian)やUTF-16BE(Big Endian)は、日本語でも検索が可能だ(写真01)。
-
写真01: 各種の文字エンコードでテキストファイルを作成した。ファイルには「日本語テキスト」という文字列が入っている。これをエクスプローラーの検索欄で検索すると、UTF-16LE/BE、BOM付きのUTF-8、シフトJISのファイルだけが検索結果となり、他のエンコード方式では検索対象にならない

UTF-8ではBOMは必須とされておらず、付けることも推奨されていない。このため、標準ではBOMを付けないUTF-8対応ソフトウェアは少なくない。UTF-8ファイルにBOMが入ること自体は明確に禁止されていない。BOM付きのUTF-8を出力可能なソフトウェアも存在するが、すべてではない。Windows 10で改良された標準アプリの1つ「メモ帳」も、最初は、BOM付きのUTF-8を出力していたが、現在のバージョンは、BOMなしのUTF-8でも出力できるようになっている。しかし、Excel 2019やMicrosoft 365版は、UTF-8テキストファイルの先頭にBOMがないとシフトJISエンコードと判断されて文字化けすることがある。そういうわけで、筆者は、ここ数年の間にUTF-8で作成したテキストファイルをWindowsではほとんど検索できない状態になってしまった。
Windowsの全文検索機能は、バックグラウンドでインデックスファイルを作成し、これを使った高速検索が可能だ。しかし、作成したUTF-8のテキストファイルの検索ができないことを考えると、インデックス作成処理自体が無駄に思えてくる。かといって、Microsoftが「Unicode」だと主張するUTF-16LEは、日本語テキストファイルの標準とは認知されておらず、WindowsのすべてのテキストアプリケーションがUTF-16のテキストファイルを正しく読み込める保証もない。またUTF-16は、サロゲートペアという問題を抱えている。そういうわけで、できれば、UTF-16は使いたくない。
検索用ファイルを作成する
そこで、UTF-8のテキストファイルから検索専用のUTF-16LEのファイルを作り、これを検索させることにした。Windowsの検索機能では、発見したファイルが置かれているフォルダーを開くことができる。“xyz.txt”というテキストファイルに対して、同じフォルダーに“xyz.stxt”という名前のUTF-16LEに変換したファイルを作れば、Windowsの検索機能で、“xyz.txt”のあるフォルダーを探すことができる。拡張子を除くファイル名の部分を同一にしておけば、元になったテキストファイルを探すのは難しくない。拡張子は他のアプリと重複しなければ、なんでもいい。筆者は、“search text”の意味で“.stxt”を使うことにした。説明の都合上、これをstxtファイルと呼ぶ。
stxtファイルを作るには、ファイルの文字コードを変換する必要があるが、これには、nkf(network kanji filter)というプログラムを使うのが簡単だ。そもそもWindowsには、標準で文字コードを変換するコマンドがない。PowerShellを使えばファイルの文字コードを変換可能ではあるが、変換元のエンコードを明確に指定する必要があるなど、ちょっと面倒だ。
拡張子「.txt」を持つファイルすべてがUTF-8になっているわけではない。過去に作ったファイルではシフトJISが使われているし、ダウンロードしたプログラムなどに付属していたテキストファイルには、EUCなど他のエンコードが使われているかもしれない。
nkfが便利なのは、比較的高い確率でファイルのエンコード方式を推測してくれるため、ファイルのエンコード方式を指定しなくても動作する点だ。nkfは、Windows用もあるが、こういうときにはLinux(WSL)を使うのが便利だ。nkfはパッケージ管理ツールで簡単にインストールできる。Ubuntu系なら「sudo apt install nkf」でインストールできる。このあたりに関しては、以下の記事を参考にされたい。
・Windows Subsystem for Linuxガイド コマンド編
https://news.mynavi.jp/article/20211228-2240002/
nkfでは、「nkf -O -w16L 入力テキスト 出力テキスト」でエンコードをUTF-16LEに変換できる。直下サブフォルダーにあるテキストファイルを全部変換するなら
for x in */*.txt; do nkf -w16L "$x" >"${x%.*}.stxt" ; done
といった感じで行え、現在のフォルダ以下で、すべてのサブフォルダーを処理するなら
find -name \*.txt -size +0 -print0 | sed -z 's/\.txt$//' | xargs -t -0 -I % nkf -O -w16L %.txt %.stxt
という感じになる。cmd.exeで、FORコマンドを使って行えなくもないのだが結構記述が面倒だ。
次に、stxtファイルをインデックス化の対象にする。これには、コントロールパネルの「インデックスのオプション」を開き、「詳細設定ボタン ⇒ ファイルの種類タブ ⇒ 新しい拡張子を一覧に追加」で「stxt」を入力して、追加ボタンを押す。すると上のリストにstxtが追加されるので、「このファイルのインデックスの作成方法 ⇒ プロパティとファイルのコンテンツのインデックスを作成する」を選ぶと、「フィルターの説明」が「プレーンテキストフィルター」に書き換わる(写真02)。その後OKボタンを押せば、拡張子「.stxt」を持つファイルは、インデックス化および検索の対象になる。これで、同じファイル名を持つテキストファイルを簡単に探せるようになる。エクスプローラーの検索機能を使って、stxtファイルを見つけたら、右クリックで「ファイルの場所を開く」を選べば、同名のテキストファイルがあるフォルダーが開く。
-
写真02: コントロールパネルの「インデックスのオプション」を開き、そこにある「詳細設定」ボタンを押す。表示された詳細オプションダイアログボックスの「ファイルの種類」タブを開き、拡張子(stxt)を入力して追加ボタンを押す。リストに登録されたstxtを選んで、「プロパティとファイルのコンテンツのインデックスを作成する」を選択すると、「フィルターの種類」がプレーンテキストフィルターになる。これで、stxtファイルを検索で探せるようになる

タイトルの元ネタは米国ドラマ「プローブ捜査指令」である。1972年に「Probe」というタイトルでパイロット版が作られたが、本放送時には「Search」というタイトルになった。捜査員が指輪に組み込んだ超小型通信機でリアルタイムに映像やセンサ情報を本部に送信、本部のコンピュータやスタッフの支援を受けながら犯罪捜査を行うという設定のドラマだ。第1世代のアナログ方式自動車電話(1979年)のサービス開始以前の番組である。当時は絵空事と思っていたが、今のスマホを見るとそれほど外れていない。