ファイルを検索するfindコマンド
ここまではlsコマンドについて説明してきましたが、実際にファイルを検索して処理しようとすると機能不足で使えない事があります。特に階層の深いディレクトリ内を再帰的に処理していく用途にはむいていません。
そこで登場するのがfindコマンドです。findコマンドは高機能でいろいろできますが、まずはカレントディレクトリ以下のファイルを検索してみましょう。以下のように入力するとカレントディレクトリのファイルやディレクトリがリストアップされます。サブディレクトリ内にあるファイルもリストアップされているのが分かります。ここらへんはlsコマンドと異なる部分です。
find .

最初のパラメータが検索を開始するディレクトリパスになります。ディスク全体を検索する場合は/を指定します。
find /


ホームディレクトリ内の検索なら以下のように指定します。
find ~


ディレクトリ内容を単に表示するだけならlsコマンドの方が短くて便利です。さすがに何かオプションを指定して検索しないとfindを使う意味がありません。
という事で、まずはファイルだけをリストアップしてみましょう。先ほどの場合はファイルもディレクトリも表示されていました。ファイルだけをリストアップするには以下のようにtypeオプションにfを指定します。fはfileの頭文字です。
find . -type f

ファイルでなくディレクトリの場合はfの代わりにdを指定します。
find . -type d

次に拡張子がtxtのファイルを検索してみましょう。以下のように-nameオプションを使って、その後に検索するファイルを指定します。この指定方法は、何度か使っているので見慣れてしまったかもしれません。ただし、ここで注意点があります。*.txtのようなワイルドカードの指定はシングルクオートで囲まないとエラーになってしまいます。これは、*がシェルによって展開されてしまうためです。
find . -type f -name '*.txt'

テキストファイルの場合、拡張子がtxt以外にtextというパターンもあります。JPEG画像ファイルにもjpgとjpegがあります。どちらの拡張子のファイルも検索したい場合は-orを指定します。以下のように指定すると拡張子がtxtとtext両方のファイルが表示されます。
なお、sampleディレクトリに拡張子textのファイルを用意するのを忘れていたので、touch 201902.textのようにコマンドを入力してファイルを作成してあります。
find . -type f -name '*.txt' -or -name '*.text'


ここで拡張子がtxtではないファイルを表示したくなりました。どうしましょう。そんな時もfindです。特定の拡張子を持つファイルを排除して検索できます。
このような場合は否定を示す!を付けます。すると今度は拡張子がtxt以外のファイルが表示されます。
find . ! -name '*.txt' -type f

拡張子がtxtおよびtext以外のファイルを検索する場合は以下のように、さらに!を使って連続で指定します。
find . ! -name '*.txt' ! -name '*.text' -type f

検索された結果をファイルに保存しておきたい場合は以下のようにリダイレクトします。
find . ! -name '*.txt' ! -name '*.text' -type f >list.txt


Webブラウザを利用する
findコマンドで検索したファイルの内容を確認したい場合はWebブラウザを利用すると便利です。
そこでfindコマンドで検索した結果をHTMLファイルにしてみましょう。HTMLにはリストを示す<ul><ol><li>タグがあります。<ol>だと自動的に表示される項目に順番に番号をつけてくれます。検索したファイル数などが分かった方が便利だと思うので今回は<ol>タグを使う事にします。
ちなみに<ol>タグを使った場合、こんな感じに項目番号が表示されます。

HTMLは以下のようになります。
<!DOCTYPE html>
<html><head><title>find</title></head>
<body>
<ol>
<li><a href="ファイルの場所">file1</a></li>
<li><a href="ファイルの場所">file2</a></li>
<li><a href="ファイルの場所">file3</a></li>
<li><a href="ファイルの場所">file4</a></li>
</ol>
</body>
</html>

ここのHTML内の<li>タグの行の内容をfindで検索したファイルパスに置き換えます。置き換えるというより、リストとして出力すると言った方が正しいでしょう。生成されたHTMLファイルをWebブラウザで開けば確認もしやすいといった具合です。
HTMLを生成する方法はいくつかありますが、まずテキストファイルを利用するパターンから説明します。
まず、HTMLの<ol>タグまでの内容をテキストファイルとして用意しておきます。ここでは、header.txtという名前にしておきます。このファイルをいつものようにデスクトップのsampleディレクトリ内に保存しておきます。ファイルの場所は~/Desktop/sample/header.txtとなります。デスクトップ上はファイルが散らかるから困るという人は、もちろん他のディレクトリに保存しても構いません。その場合は以下のファイルパスを適宜読み替えて下さい。なお、シェルスクリプトにしてしまえばechoコマンドでHTMLを出力すればよいので、このようなファイルは不要になります。
・header.txt
<!DOCTYPE html>
<html><head><title>find</title></head>
<body>
<ol>
もうひとつHTMLの</ol>以下の内容をfooter.txtという名前でheader.txtと同じ場所に保存しておきます。
・footer.txt
</ol>
</body>
</html>

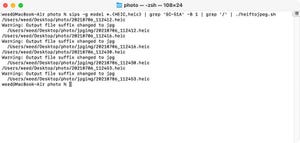
それでは順番に作っていきましょう。まず、拡張子がtxtのファイルを検索します。すでに説明済みですが、カレントディレクトリ以下のファイルを検索する場合は以下のようになります。
find . -type f -name '*.txt'

次に検索した結果をlist.txtというファイル名で保存します。リダイレクトを使って以下のように指定します。
find . -type f -name '*.txt' > list.txt

このファイルの中身は以下のようになります。

すべての行頭に<li><a>タグを付けるので以下のようにします。sedを使う場合だと以下のようになります。標準入力から読み込んだ行を正規表現を使って置き換えていきます。^は行頭を示す正規表現の記号です。同様に.は任意の1文字を示し、.*とすることで丸ごと1行を示すことになります。ここでポイントになるのが( )のグルーピングです。正規表現では( )を使って囲んだ場合、その()内にマッチした内容を\1や\2のようにバックスラッシュの後に1桁の数値を指定して再利用することができます。最初に( )で囲まれマッチした部分が\1、二番目に( )で囲まれマッチした部分が\2のようになります。これを使えばURLを示す文字列とブラウザで画面に表示する部分の文字列を\1として指定できます。
cat list.txt | sed -e "s/^\(.*\)/<li><a href='\1'>\1<\/a><\/li>/"

出力結果を確認して問題なければ一旦テキストファイルとして保存しておきます。とりあえずbody.txtという名前でカレントディレクトリに保存します。
cat list.txt | sed -e "s/^\(.*\)/<li><a href='\1'>\1<\/a><\/li>/" >body.txt

これでリスト部分ができたのでヘッダー、フッターのファイルを連結しHTMLファイルを生成します。ここではfilelist.htmlという名前でカレントディレクトリに保存します。
cat header.txt body.txt footer.txt >filelist.html

正規表現されたfilelist.htmlをWebブラウザで開くとファイル一覧が表示されます。そして、ファイル名をクリックすると該当するファイル内容が表示されます。



シンプルですが、なかなか便利です。もっとも、これはWebブラウザあっての便利さです。Webブラウザが登場する前、つまり最初のブラウザであるMosaic(モザイク)が出る前は、こういうファイル内容を手軽に見るというのも、なかなか難しかったのです。
著者 仲村次郎
いろいろな事に手を出してみたものの結局身につかず、とりあえず目的の事ができればいいんじゃないかみたいな感じで生きております。