2025年の幕開けに、パーソナルコンピュータのハードウェア技術の動向を占う毎年恒例の特集記事「PCテクノロジートレンド」をお届けする。まずは例年通り、業界のあらゆる活動に大きな影響を及ぼす半導体プロセスの動向、なかでもTSMCの動向から紹介したい。
|
◆関連記事リンク (2025年1月1日掲載) PCテクノロジートレンド 2025 - プロセス編「TSMC」 (2025年1月2日掲載) PCテクノロジートレンド 2025 - プロセス編「Samsung」「Intel」 (2025年1月3日掲載) PCテクノロジートレンド 2025 - CPU編「Intel」「AMD」 (2025年1月4日掲載) PCテクノロジートレンド 2025 - GPU編「NVIDIA」「AMD」「Intel」 (2025年1月5日掲載予定) PCテクノロジートレンド 2025 - Memory編 (2025年1月6日掲載予定) PCテクノロジートレンド 2025 - Storage編 (2025年1月7日掲載予定) PCテクノロジートレンド 2025 - Chipset編 |
|---|
***
皆様、あけましておめでとうございます。本年もよろしくお願いします。当然ながら、筆者はまだ年が明けておりません。
TSMCの2025年、最大のトピックはN2の量産開始
さて恒例プロセス編から始めたいと思う。2024年は結果から言えばTSMCの一人勝ちになってしまった訳だが、果たして2025年にSamsung/Intelはこれに一矢報いることが出来るかどうか、というあたりがポイントである。というわけで、まずはTSMCから。
-
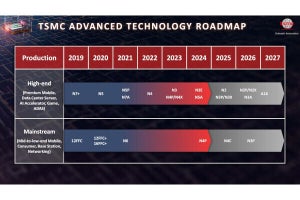
Photo01: 内容的には2024年4月から各地で開催されたTSMC Technology Symposiumのものと違いはない。

Photo01は2024年10月に開催されたTSMC OIP Forum Japanで示されたスライドであるが、2024年はN3E、それとN5Eの立ち上げが行われた。もっとも立ち上げというか量産開始と、そのプロセスを利用した製品の市場投入開始の間には当然差が出る。PCあるいはServerマーケット向けに関しては、2024年はN4ベースの製品どまり。N3Bに関してはIntelがArrow LakeのCPU Tileで採用し、既に出荷が開始されているが、Arrow LakeのCPU Tileのサイズは114.5平方mm程度とされている。この面積だと、1枚の300mm Waferから取れる最大数は536個程になる計算だが、Yieldが不明である。そもそもTSMCのN3Bは当初AppleがA18/A18 Proに利用する予定だったのが、Yieldの悪さからAppleがN3Eに切り替えてしまい、結果として空いたラインをIntelが利用したという曰く付きのプロセスである。昨年のロードマップでは、N3BをAppleが利用すると書いたが、結果的に2024年に登場したA18/A18 ProはN3Eしていることからもこれは明らかだ。
さてそんなA18/A18 Pro、N3BのD0(Defect Rate)を例えば0.3と仮定するとA18 ProでYieldは73.6%、A18では76.8%と結構高い。この程度だとN3Bを嫌ってN3Eにする理由がない。では0.4だと? というと同じく66.7%/70.0%となり、まだ微妙な線。では0.5では? というと60.6%/64.9%まで落ちる。多分このあたりが実際のDefect Rateに近いのだろう。仮にこの0.5を当てはめると、Arrow LakeのYieldは58.0%まで落ちる。つまり536個製造しても、使えるダイは299個だ。まぁそれでも1000枚作れば30万個近いCPU Tileが取れる訳で、Arrow Lakeだけであれば製造には十分であろう。逆に言えば、このD0で例えばSapphire Rapidsみたいに巨大なダイ(20mm×20mm)を作るとどうなるか? というと、148個のダイのうち良品は27個、Yieldは実に18.7%まで落ちる。D0が0.4で24.9%、D0が0.3で33.9%である。巨大ダイの製造にはまるで向いていないというか、相当頑張らないといけない感じであるが、TSMCは既にN3Eとこれに続くプロセスに開発を注力しているから、N3Bは本当にもうピンポイントというか、Arrow Lakeとその他幾つかの製品の製造に留まり、長期的にはN3E以降に誘導してゆく形かと思われる。
で、2024年はApple A18/A18 Proのみ市場に投入されたわけだが、こちらはApple以外にAMDやNVIDIA、Qualcomm、その他多数のメーカーが狙っている。ここにはBroadcomとかMarvellも含まれており、両社のデザインサービスを利用したチップがAWS、Google、Meta、Microsoftなどからも2025年に登場してくるのは間違いない。ただそのN3Eのキャパシティも限られているから、各社とも2025年に入って製品発表は行ったとしても、実際に市場投入までにはちょっと時間が掛かりそうである。
さてPhoto01に戻ると、2023年末のロードマップと比較した場合にN3Pが2024年送りになったが、これは提供時期が遅れたというよりも、需要の立ち上がりが2025年まで遅れたという方が正確なのではないかと思う。このN3PはQualcommがSnapdragon 8 Elite Gen 2の量産に使うとされている。PC向けで言うと、GPUの中にはこれを使うものが出てくるかもしれない。ただ2025年中に出てくるCPUは、IntelはN3BとIntel 18Aの予定。AMDはZen 6ベースのMedusaはN3Eで確定なので、N3Eを利用するPC向けプロセッサが出て来るかどうかは怪しい。可能性としてはIntelのBackup(Intel 18Aが駄目だった場合の代替)、それとAMDが途中からN3E→N3Pに移行する可能性だが、前者は兎も角後者は可能性としては低いとは思う。あるとすれば、Ryzen Mobileの方で、Sound Wave(?)というZen 6ベースの次世代Ryzen MobileがひょっとするとN3Eの次ということでN3Pベースになる可能性はあるが、こちらはそもそも2025年中に出て来るかどうかも怪しいところだ。
N3Xの方は、プロセスとして存在はするのかもしれないが、使うとしても一部のAI向けプロセッサのみという事になりそうな気がする。N3XはN3比で15%の性能向上と4%のロジック密度向上を実現したプロセスとなっているが、その代わりに消費電力が大幅に増える。昨今はHPCのみならずAI向けプロセッサであっても、性能/消費電力比を高める事でランニングコスト(主に電気代)を抑えるのが必須とされる現状にあって、N3Xの様な特性は非常に使いにくい。勿論ピーク性能ではなくもっと動作周波数(と電圧)を抑えれば効率は改善されるが、そうした使い方の場合N3EとかN3Pと比べてどこまでアドバンテージがあるのかは明確ではない。勿論一部、消費電力より性能優先というケースはあるだろうから、そうした用途向けに使われるかもしれないが、あんまり広範に使われることは無さそうに思われる。
さてその2025年の最大のトピックはN2の量産開始である。既に2024年第3四半期にTechnical Qualificationは完了。第4四半期にはRisk Productionもスタートしており、2025年後半に本格量産に入る。といっても最初は恐らくApple向けという事もあり、PC向けの製品の製造に入れるのは2026年から。これを搭載した製品が市場出荷されるのも、恐らく2026年後半(というか年末に近いあたり)になるだろう。N3Eと比較して同じ消費電力なら10~15%の性能向上、同じ動作周波数なら20~25%の消費電力削減が可能で、ロジック密度が15%以上向上するとしている。2024年12月に行われたIEDM 2024における発表(2-1 2nm Platform Technology featuring Energy-efficient Nanosheet Transistors and Interconnects co-optimized with 3DIC for AI, HPC and Mobile SoC Applications)でも、N2の品質に問題が無い(Photo02~03)事をアピールしている。
ちなみにPhoto02のSRAM cellの話だが、別のスライドではHD SRAM Macroの密度が38.1Mb/平方mmと報告されている。Photo02もHD SRAMだとすれば、256MbitのSRAM Cellの面積は6.7平方mmほど。純粋にこのSRAM Cell「だけ」だと、D0が1.5(1平方cmにDefectが1.5個)でもYieldが90%とかになってしまうのだが、SRAMに加えて読み出し回路などを構成するともう少し大きくなる。10平方mmほどまで大きくなるとD0が1.0でギリギリYield 90%であり、Peak Yield 95%を実現しようとするとD0が0.4あたりまで下がらないと難しい。恐らくはこの辺が現在のN2の状況ではないかと思われる。
-
Photo02: 256Mbit SRAM cellのSHMOOの結果。ピークのYieldが95%とされる。

-
Photo03: 信頼性検査の結果。全項目が合格だったとしている。

ちなみにN3ではFinFlex(動作パラメータに応じてFinの数を変更する)が用意されていたが、N2ではNanoFlexと呼ばれるものが用意されるという話があった。2024年7月に開催されたTSMC 2024 Japan Technology Symposiumの折にこの詳細を確認したものの返事が無かったが、今回NanoFlexはShort cellとTall cellの組み合わせから実現されることが明らかになった(Photo04)。ただ論文でもShort cellとTall cellの違いは明らかにされていない。もっともPaperを見ると"N2 NanoFlex standard cell innovation offers not only nanosheet width modulation but also the much desired design flexibility of the multi-cell architecture."とあり、Sheetの幅が違うのは確定で、あとはRibbonの数の調整ということなのかもしれない(厚みを増やすという選択肢は無いと思いたい)。そのNanoFlexを利用した場合の特性をN3Eと比較したのがこちら(Photo05)で、同じ動作周波数なら35%の消費電力削減、同じ電力なら14%の高速化が実現出来た、としている。
少なくとも現状、このN2に関して量産に至るまでの障壁は殆ど残っていない模様だ。最後の障壁は? というと価格で、以前は1枚あたり$25,000程度とみられていたWafer Cost、最近の報告では$30,000近いらしい。これはチップ価格の猛烈な上昇に繋がると思われるだけに、N2を使うアプリケーションは相当注意深く選ばれる事になりそうだ。
-
Photo04: この文面からすると、基本はShort cellで、部分的にTall cellを組み合わせるように見える。逆にTall cellだけという選択肢は無いようだ(将来のN2XとかがTall cellのみを基本とするのかもしれないが)。

-
Photo05: PaperではCPUとGPU、SoCからなるTest Chip(30億トランジスタ)を製造して検証とあり、このCPUがCortex-A715という事かと思われる。

さてこれに続き、2026年にはN2P/N2Xが登場する事になっている。実はこのN2P/N2Xはあまり情報が無い。一応N2PはN2Eと比較して5~10%程度消費電力が少ない(恐らく同一動作周波数の場合)という情報はあるが、逆に同一消費電力で動作周波数がどの程度伸びるのかという数字が無いあたり、単に消費電力削減がメインの可能性はある。もっともそれで5~10%減るなら、それは十分大きな改良ではあるのだが。ちなみにN2Eからデザインの互換性がある、とされている。同時期にN2Xも提供される筈だが、こちらの詳細は本当に不明である。この辺は2025年のTSMC Technology Symposiumでもう少し公開されるかもしれない。ちなみにこのN2に向けたEDA Tool(Photo06)やIP(Photo07)の準備もかなり進んでおり、2025年にはN2シリコンでの試作して検証が完了したIPのアナウンスとかがありそうだ。
-
Photo06: 2024年10月現在の状況。まだV0.9ということだが、今年中にV1.0に到達するだろう。

-
Photo07: 同じく2024年10月現在の状況。M31というのは台湾の円星科技(M31 Technology Corporation)。アンドロメダ星雲に因んだ名前と思われる。

そして2026年末~2027年に登場するのがA16プロセスである。このA16はトランジスタの改良に加え、BSPDN(Back-Side Power Delivery Network:裏面電力供給)オプションが付く最初のプロセスとなっている。以前はN2P/N2Xで提供されるのでは? という話もあったが、これはA16まで後送りにされることになった。A16とN2Pの性能差は以前こちらに掲載したものから特に変わっていない。
後工程に関しても少しだけ
さて、前工程についてはこんなもんであるが、後工程に関しても。といっても基本的にこれ以上の話は無いのだが。ただこの図ではCoWoS-S(Silicon Interposer)→CoWoS-R(Organic Interposer)に推移するという話しか載っていないが、この間を埋めるものとしてCoWoS-Lが以前からTSMCのページで紹介されている。
このCoWoS-Lは要するにSilicon Interposerを利用したBridge(Photo08)で、IntelのEMIBとかSamsung ElectronicsのI-Cube E、SPILのFOEB(Fan Out Embedded Bridge)、あるいはASEのFOCoS-Bridgeなどと各社から提供されている技法だが、TSMCはNVIDIAのBlackwellの接続でこれが初採用となった。その結果、というのもあれだが2024年8月頃に伝えられたBlackwellの遅延の理由がまさにこのCoWoS-Lの問題だったらしい。
-
Photo08: TSMCのCoWoS-Lのページで示されている図。RDLの中にSilicon Interposer(LSI同士の接続、あるいは間にPassive Deviceを埋め込んだもの)が利用さえるイメージ。

まぁ最初だから仕方がないところではあるかと思うが。Blackwell Superchip場合、Blackwellのダイ(凡そ850平方mm)×2+HBM3E×8が一つのパッケージに入る。つまりダイだけで1700平方mm、HBM3(11mm×11mm)×8を加味すると2668平方mmほど。先程のスライドに出て来た、2023年の3.3倍の枠では収まりきらない。2026年のCoWoS-SならReticle Limitの5.5倍までいけるからギリ収まったと思うのだが、2023年の80mm角では無理で、それもあってCoWoS-Lを選んだものと思われる。
ちなみにこのCoWoS-Lの問題は解決したらしいのだが、今度は発熱過多(以前はGB200 NVL72は120KWの消費電力とされていたが、これが140KWに上方修正され、結果として冷却システムなどの再設計が必要になったらしい)でまた遅れており、製品の量産出荷は2025年に入ってからに後退したらしい。まぁこれは余談である。ただ結果としてTSMCはCoWoS-SだけでなくCoWoS-Lも実際に量産採用例が出来、またSoICやWoW(Wafer on Wafer)では今のところそれを提供できる唯一のベンダーとなっているという事もあり、この2.5D/3Dのパッケージ技術でも独占的な地位を築いている。
問題は生産能力である。2024年12月にロイターなどが報じた話は、TSMCのアリゾナ工場で製造したチップ(Blackwellがまさにここで製造されるらしい)であっても、そのPackagingに関しては一度台湾に戻す必要がある事を報じている。これは別に珍しい話ではなく、アリゾナは本当に前工程だけの製造になっているからだ。ただこれは逆に言えば台湾のパッケージ向けラインが逼迫しやすいという意味でもあり、特にSoICやWoWなどの先端的なものに関しては少なくとも2025年中に台湾以外の場所で可能になることはないだろう(CoWoS-Sに関しては、サイズが小さいものに関しては熊本のJAMSなどに移管される可能性が無いとは言えない)。結果、2025年もファブレスメーカーはTSMCの生産枠を取り合いながら量産を進めるという構図に変わりはないものと考えられる。