この提案されたアルゴリズム(提案手法)は、2020年にGoogleが発表したディープラーニングによる画像認識モデルで、自然言語解析の分野で開発されたSelf-Attention構造に基づくTransformerを画像認識へ応用したもので、従来とは大きく異なる構造で高い精度を達成したことから注目されるようになったViTに基づいているという。
具体的には、重なり合いを持つパッチ化モジュールを用いた多段階のトランスフォーマーブロックの構造に新規性があり、これによって画像の特徴を階層的な表現で効率的に学習できるとするほか、機械学習を用いた反復不要な処理アルゴリズムであることから高速処理も可能。加えて、物理モデルをコンピュータが学習するため、モデル近似誤差の影響を減らすことができるほか、画像内の大局的な特徴量を利用するため、イメージセンサーの広い範囲にわたる投影パターンの処理に適しているという。
光学実験の結果、提案された再構成法を用いたレンズレスカメラは、ほかの手法よりもノイズが少なく鮮明な画像を生成することに成功したほか、処理の計算速度も十分速く、リアルタイムでの撮影も可能であることが確認されたという。
-
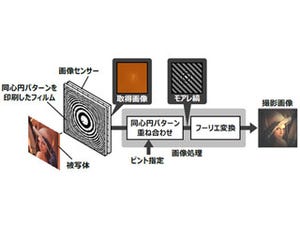
(上)光学実験に使用したレンズレスカメラ。レンズレスカメラは、マスクと2.5mm離れた位置のイメージセンサーで構成されている。マスクは、開口サイズ40μm×40μmの合成石英板にクロムを蒸着して作製された。(下)レンズレス撮影の流れ。マスクを通してイメージセンサー上にパターンを投影した後、数学的なアルゴリズムによって画像が再構成される (出所:プレスリリースPDF)

なお、研究チームでは、レンズレスカメラの利点は小型化だけではなく、レンズの製造が難しい不可視光イメージングへの適用や、マスクを通じて撮影した画像からワンショットでの3D撮影への応用などにも発展可能だとしており、次世代画像センシングソリューションの新たな方向性として、これからのIoTの進化を支えることが期待されるとしている。
-
光学実験結果。撮影対象は、液晶画面に表示された画像(左2列)と、実物体(右2列)。1行目は、液晶画面に表示された原画像と、実物体の撮影風景。2行目はセンサーに撮影されたパターン。最後の3行は、今回提案された手法、モデルベース手法、CNNベース手法による再構成画像。提案手法は、最も高品質でノイズが少なく鮮明な画像を生成できている (出所:プレスリリースPDF)