各国が進めるエクサスケールプロジェクト
次の図は各国のエクサスケールプロジェクトの一覧である。アメリカはピーク性能がエクサスケールのシステムを2021年に稼働し、2023年にはアプリケーションの実行性能でエクサFlopsを超えるシステムを実用化する計画である。各システムは3億ドル~6億ドルのコストで、それに加えてR&Dにかなりのコストがかかると見積もられている。
EUも、ピークがエクサスケールのシステムを2021年、実アプリでのサステイン性能がエクサスケールのシステムを2022年から2023年に実用化する計画である。
そして、中国は、アメリカより1~2年早く、ピークでエクサスケールのシステムを2020年、アプリのサステイン性能でエクサの性能を2021年~2022年に実用化する計画である。
日本は、Flagship 2020プロジェクトで、2022年にエクサスケールのシステムを稼働させる計画である。R&Dと1システムの製造コストの合計は8億~10億ドルと見積もられている。
-
世界各国のエクサスケールプロジェクト。2021年から2023年にアプリケーション性能で1ExaFlopsを目指す

中国は、無錫の太湖之光をアップグレードする計画と天河2号を作った国立科技大が数100PFlopsにアップグレードした天河2号Aを開発する計画があり、それに加えて中国科学院計算技術研究所とタイアップしてSugon(中科曙光)が数100PFlopsマシンを開発する計画があるという。
米国は2021年にエクサスケールシステムを出荷
米国は、ピーク性能でエクサスケールのシステムを2021年に出荷し、ECPプロジェクトの成果に基づくアプリでエクサスケールのシステムを2022年から2023年に完成する予定である。
-
中国と米国エネルギー省のエクサスケールプロジェクト。中国では3つのプロジェクトが並行して走っている

エネルギー省の次期の大規模システムは、Oak RidgeとLawrence Livermore国立研究所の設置されるIBMとNVIDIAが開発するシステムである。IBMのPOWER9 CPUとNVIDIAのV100 GPUを使うシステムで、現在、設置を行っている最中であり、2018年6月のTOP500リストには登場すると見られている。
7.5TFlopsの計算ノードを4600ノード持ち、ピーク性能は200PFlopsを超える。現在使用しているTitanスパコンの5~10倍の性能と見積もられている。
そして、2021年にはArgonne国立研究所にIntelが開発する「Aurora 21」が納入される予定になっている。このシステムはKnights Hillではなく、その次のアーキテクチャのIntelのHPCプロセサを使うと言われているが、どのようなプロセサであるのかは明らかにされていない。
-
米国では次期フラグシップスパコンの開発に、IBM-NVIDIAのSummitとIntelのAurora 21という2つのプロジェクトが行われている。Summitは、設置の最中で、2018年6月のTOP500に登場する見通し

時代に併せて変化するスパコンのベンチマークツール
HPLはスパコンの性能ランキングツールとして大成功を収めたのであるが、最近では、HPL性能と実アプリケーションの性能と乖離が目立ってきている。そのため、HPL性能を高める設計が実アプリケーション性能を高める設計にならない。
そして、このHPLと実アプリケーション性能の乖離は将来的に増加すると考えられる。このため、HPLとは異なる性能評価法が必要であると考えるに至ったという。
-
HPL性能と実アプリケーション性能の乖離は、今後、さらに増加していくと考えられる。このため、HPLとは別の性能指標が必要になる

このように考えて作られたのが、HPCGベンチマークである。HPCGもHPLと同様に巨大な連立一次方程式を解くプログラムである。しかし、大きく異なるのは、HPLは大部分の係数が非ゼロの密行列の解を求めるのに対して、HPCGは大部分の係数がゼロのより大きな疎行列の解を求めるという点である。
HPLは変数を1つずつ消去していくガウス法ではないが、解析的に解を求める。一方、HPCGは適当な解を想定して誤差を計算し、誤差を小さくするように想定した解を修正するというループで、実用的に正しい解を得る。
また、HPLでは係数は連続領域に格納されているが、HPCGでは大部分の係数はゼロであるので、ゼロの部分を圧縮した格納形式を使わないとメモリの利用効率が悪い。
このため、同じ巨大連立一次方程式を解くのであるが、HPLとHPCGではまったく異なった解法が用いられ、HPLではメモリバンド幅はあまり問題にならないのに対して、HPCGでは飛び飛びのアクセスでのメモリバンド幅が問題になる。
なお、この説明は単純化し過ぎで、HPCGでは密行列の処理が必要になる場合もある。
-
別の指標として、HPCGを提案している。HPCGも連立一次方程式を解くが、密行列ではなく、巨大な疎行列を解く

ソフトウェアがスパコンの性能を左右する時代が到来
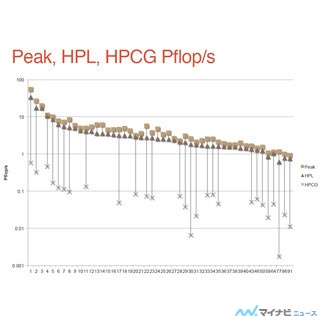
次の表はHPCG性能のTOP10をあげたものであるが、第1位は京コンピュータ、第2位が天河2号、第3位はアメリカのTrinityである。この表の、右から4番目の列がHPL性能、その右の列がHPLの性能ランキング、続いてHPCG性能、ピーク演算性能に対するHPCG性能の比率が書かれている。
HPCGでは飛び飛びのメモリアクセスの性能が重要になるため、大多数のシステムで、ピーク演算性能の2%以下の性能しか得られていない。これはピークの60%以上の性能が得られるHPL性能と大きく異なる。
その中で、京コンピュータはピークの5.3%の性能が得られているので、HPCG性能では第1位となっている。一方、太湖之光はピーク演算性能はダントツに高いものの、その0.4%の性能しか得られていないため、HPCG性能では5位に留まっている。
-
HPCG性能のTop10リスト。第1位は京コンピュータである。右から3番目の列がHPLでの性能ランキング、続いてHPCG性能とピーク演算性能に対するHPCG性能のパーセンテージ

次の図の上側の線は、TOP500のシステムのピーク性能とHPL性能のプロットで、下の線がHPCGの性能をプロットしたものである。大局的にはHPLの高いシステムはHPCG性能が高いともいえるが、HPCG性能のプロットには大きなバラつきがある。そして、HPLとHPCGの性能には、ざっと2桁の違いがある。
このため、Dongarra先生は、HPLとHPCGは性能評価の両側のブックエンドであると言っている。HPLはピーク演算性能に最も近い実アプリケーションであり、HPCGはメモリアクセスが制約となり、発揮できる演算性能が最も低いアプリケーションであり、その他のアプリケーションは、このブックエンドの両端の間に入るという。
-
HPL性能とHPCG性能をプロットした図。横軸はHPL性能のランキングである。HPCG性能は、HPL性能より2桁低い性能になっている。HPL性能は、実アプリケーション性能の上限、HPCG性能は下限を示す両端のブックエンドと言える

結論であるが、現在は、HPCにとって興奮させられる時代である。そして、直前の数十年はハードウェアの性能向上に重点が置かれたが、現在はソフトウェアの進歩が制約になってきており、重点の置き方は再考されるべきであるという。
-
現在はHPCにとって興奮させられる時代である。以前の数十年はハードウェアの研究が主体であったが、現在はソフトウェアの方が制約になってきており、研究の力の入れ方を考え直すべきである