今回はWindows 10ではなく、Microsoftの研究機関であるMicrosoft Researchの話題を取り上げたい。筆者が初めてコンピューターから流れる音声を耳にしたのは、1980年代の「マイコン」時代。「PC-6001」と名付けられたコンピューターは追加ユニットを用いることで、PSGを用いた音声合成を可能にしていた。もちろん、事前にBASICなどから話す内容をプログラミングしなければならず、SF映画のように人とコンピューターが会話する世界は夢のまた夢だった。
だが、あらためて周りを見渡すと現在は、iOSやAndroidの音声入力、SiriやOK Googleによる音声操作、Cortanaは音声でスケジュール管理を可能にした。2016年後半あたりから「音声の時代」と言われはじめ、Google HomeやAmazon Echoといったスマートスピーカーも台頭してきている。MicrosoftはCortanaへのアクセスをサードパーティーに提供し、Harman KardonのInvokeなどが今年中に海外で発売される予定だ。

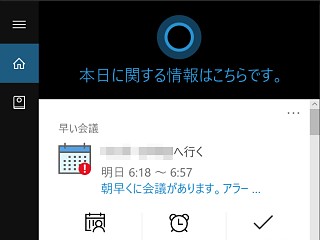
|
「Invoke」を紹介するHarman Kardonのトップページ。2017年秋リリース予定と書かれている |
Cortanaは2009年から開発をスタートしているが、その背景にはMicrosoft Researchが長年を費やした研究結果がある。音声認識分野では、2016年10月に単語エラー率が5.9%まで低減したことを明らかにした。これは、インタビュー原稿を書き起こすプロフェッショナルよりも低いエラー率であり、ある意味「人を超えた」とも言える性能だ。
だが、Microsoft Speech&Dialog Research GroupのGeoffrey Zweig氏は、「すべての単語を完璧に認識できる訳ではない。今回注目すべきは『have』を『is』、『a』を『the』と聞き違えるエラー率が人と同等になったことだ」と述べている。

|
Microsoft Speech&Dialog Research Groupの面々。後方左から2番目がGeoffrey Zweig氏 |
さらに、8月20日の公式ブログ記事によると単語エラー率は5.1%まで低下した。Microsoft Technical FellowのXuedong Huang氏によると、この技術革新は深層学習用フレームワークであるMicrosoft Cognitive Toolkit(CNTK)や、Microsoft Azureインスタンスの中でもGPUを有効にしたNシリーズが大きく貢献したという。
では、これらの成果が我々の生活やビジネスシーンをどのように変えていくのだろうか。Microsoftはすでに音声認識技術を、CortanaやMicrosoft Cognitive Services、PowerPointの字幕追加機能や翻訳機能「Presentation Translator」に活用している。前述した発表内容は研究結果のため、実装までには時間を要するが、ここ1年内でUIのあり方が変化するのは確実だ。

|
日本語を含む11カ国語に対応する「Presentation Translator」 |
多くのビジネスリーダーが「音声の時代」と述べる理由の一つはUIである。我々はコンピューターを操作する上で、キーボードというCUI環境、マウスを用いたGUI環境、スマートフォンに代表されるタッチUIを使用してきた。
そして次に来るのが、音声UIとされているが、「年配層にSiriは難しい。人の口癖といった特徴まで理解するレベルになれば、銀行の窓口でも利用可能になる」との声もある。Microsoftもその点は重々理解しており、騒々しい環境でマイクから音声が聞き取りにくいケースや、訛りの強い音声の認識レベル向上を目指すと同時に、会話に含まれた意味や意図を理解するといういくつかの課題を掲げている。
技術研究が先行する英語圏は、ファストフードのドライブスルーで、AI (人工知能) と音声認識で注文を受け付けるケースも増えつつある。前述したスマートスピーカーも好評のようだが、日本語を母語とする我々は、その恩恵を受けることはない。そのため、総務省は官民合同で日本語音声認識AIの開発策定を目指しているが、前述のとおり音声認識はMicrosoftに限らず、AppleやGoogle、Amazonといったグローバル企業が取り組んでいる。この状況を打開するのは厳しいと見るのが自然ながらも、それぞれが切磋琢磨して新しい世界を作り出してほしい。人々の暮らしを豊かにすることが技術革新の真骨頂だ。
阿久津良和(Cactus)