POWER9プロセサの性能
次の棒グラフはPOWER8とのソケットあたりの性能比較で、浮動小数点演算アプリでは1.6倍弱であるが、グラフ処理アプリでは2.3倍程度、平均的には1.7~1.8倍程度の性能となっている。

|
|
各種アプリケーションでのPOWER8との性能比較。全体として1.7~1.8倍程度の性能となっている |
POWER9ではエネルギー管理も改善されている。コアがアイドル状態に移行するのに必要な時間は1/10に短縮されている。また、チップ上に作られたコントローラの制御でコアのクロックと電源電圧を制御することにより、50%の電力で80%の性能を出すことができるようになったとのことである。
また、各コアの電力消費を計算して、余裕がある場合は、その電力を優先度の高い処理を行っているコアにつぎ込んで、最大30%クロックを上げることが出来る。

|
|
POWER9では電源制御が改善され、アイドル状態への移行が10倍速くなった。また、DVFSの改良で、50%の電力で80%の性能が得られるようになった。また、コアの合計電力に余裕がある場合は、その余裕を優先度の高い処理を行っているコアにその電力をつぎ込んで、最大30%クロックを上げることができる |
POWER9のアクセラレータ接続
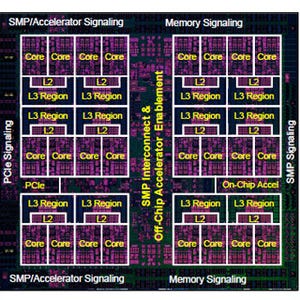
POWOR9では、アクセラレータのサポートが大幅に強化されている。PCI Express 4.0を48レーン持ち、この部分のバンド幅は192GB/sとなっている。また、25Gbpsのレーンを48レーン持ち、この部分のバンド幅は300GB/sである。NVLink2.0やOpenCAPI 3.0のアクセラレータ接続は、この25Gpsリンクを使用する。また、NVLink2.0やOpenCAPI 3.0では、CPUのキャッシュとアクセラレータのCAPIメモリがコヒーレントになりデータ転送が自動的に行われるので、アクセラレータの使い勝手が向上する。

|
|
PCIe4.0を48レーン、25Gbpsレーンを48レーン持ち、双方向のバンド幅は、それぞれ192GB/s、300GB/sとなる。また、NVLink2.0やOpenCAPI 3 .0ではCPUのキャッシュとアクセラレータのCAPIメモリがハードウェア制御でコヒーレントになり、使い勝手が向上する |
アクセラレータメモリをコヒーレントに制御するCAPIの制御機構はPOWER9チップに搭載される。CAPI 2.0はPCI Express 4.0を使うことにより、POWER8の4倍のバンド幅となる。OpenCAPIはコンソーシアムを作って他社にも採用を働きかけているオープン仕様のインタフェースである。
なお、この図では25Gリンクを使うOpenCAPI 3.0は200GB/s、PCIe4.0を使うCAPI 2.0は128GB/sと書かれており、前の図の300GB/s、192GB/sと異なる数字となっている。前のページの数字は、それぞれのリンクの最大転送速度で、このページの値は、CAPI 2.0やOpenCAPI 3.0のプロトコルオーバヘッドを考慮して、実質的に得られる転送速度を示していると思われる。

|
|
アクセラレータメモリのコヒーレンスを制御するロジックはPOWER9チップの中に組み込まれ、PCIe4.0あるいは25Gbpsのリンクでアクセラレータと接続する |
まとめ
認知コンピューティングをサポートする能力の実現のためにはそれに特化したコンポーネントやアーキテクチャが必要である。
POWER9のコアやアーキテクチャは、これからのワークロードを考えて設計されている。そのため、アクセラレータを接続して使うヘテロジニアスなコンピューティングがやり易いように作られている。さらに、大量のデータを扱うためのバンド幅や能力を持っているなどの点で、認知コンピューティング用に開発されたCPUである。
認知コンピューティングのワークフローやアプリケーションは、今後、急速に進歩すると予想されるので、システムの柔軟性が重要である。専用のシステムは変更を行うのが大変であったり、変更を行うのに時間が掛かったりする。プログラマの使い勝手、アクセラレータの構造や接続ポイントを良く考える必要がある。と述べて、Burns氏は基調講演を締めくくった。

|
|
IBM Burns氏の基調講演のまとめ |