COOL Chips 20において、IBM研究所のSystems Architecture and Design部門ディレクタのJeffrey Burns氏が基調講演を行った。「POWER9」はCognitive Computing(機械学習などを含む認知コンピューティング)を志向するプロセサであり、設計もそれに合わせたものとなっているという。
コグニティブ(認知)コンピューティングは、ディープラーニング、グラフ解析、ロボティックス、DSPなどを含む。画像の認識には1018(1Exa)Flops以上の計算が必要であり、複数言語のスピーチの学習には107時間以上の処理が必要である。
したがって、認知コンピューティングには認知アルゴリズムと機械学習のテクニックが必要であり、これらを端末側で実行することも必要となる。
一方、CMOS/シリコンテクノロジの高性能化は鈍化しており、要求される性能と比べると、何ケタも低い性能のものしか作れないという問題があるという。

|
|
認知コンピューティングで画像を認識するには1ExaFlops以上の計算が必要であり、現在のテクノロジでは実現できない (このレポートのすべての図は、IBMのBurns氏の基調講演スライドのコピーである) |
認知コンピューティングではデータ量が鍵である。この、必要なデータ量は膨大である。例えば油田探査の場合、調査で得られるデータは15PBで、そのデータの処理には10カ月以上かかる。
また、遺伝子解析に基づくパーソナル化医療に対する期待は大きいが、遺伝子データは膨大で、大きな医療機関では1-2年間に100PB以上のデータが集まる。この解析には、大型クラスタだけでなく大規模SMP(Symmetric Multi-Processor:共通メモリのマルチプロセサ)も必要である。そして、高性能のファイルシステムも必要となる。
金融関係も4TB/日のデータが集まる。そして、1日に400Mトランザクションを処理する必要があり、トランザクションに対しては100ms以下のレスポンスが要求される。
このように、認知コンピューティングでは膨大なデータを高速で処理することが必要になる。

|
|
認知コンピューティングの鍵は大量のデータである。大量のデータを高速に処理できるシステムが必要になる |
次のグラフはx86とPOWER、メインフレームのzシリーズプロセサのクロックの年次推移を示すものである。全体としてクロックは上がっているとも言えるが、微細化による性能向上だけでは認知コンピューティングの性能要求にはとても間に合わない。このため、業界はコア数を増やして性能をあげる方向になっているが、これも電力やチップ面積の制約があり十分ではない。
したがって、認知コンピューティングには専用のアクセラレータの接続と巨大データを扱える能力が必要であるという。

|
|
CPUのクロック周波数は、大きな向上はできず、認知コンピューティングの要求には追い付けない。したがって、アクセラレータが必須である |
アクセラレータは特定の処理を、汎用コンピュータより大幅に効率良く(高速あるいは低電力で)処理することができるものである。いろいろなアクセラレータが可能であり、アクセラレータの実装や、システムにどのように取り付けるのかもいろいろな選択肢がある。
重要なことは、アクセラレータの開発コスト、アクセラレータハードウェアのコストと運営コスト、プログラマから見た使い勝手などがバランスした解になっていることである。

|
|
アクセラレータと言ってもいろいろな作り方があるし、アクセラレータをどこに接続するかにも多くの選択肢がある。バランスのとれたシステムが作れることが重要 |
次のグラフの横軸は特に意味は無く、エネルギー効率の低い方から順に並べたものである。左側のマイクロプロセサは、汎用性は高いが、エネルギー効率はせいぜい0.1MOps/mW程度である。DSPやFPGAは中央の領域でマイクロプロセサの10倍程度のMOps/mWとなっている。そして、専用に設計されたハードウェアはFPGA/DSPに比べて100倍のMOps/Wが得られるという。
なお、Microsoftのデータセンターに使われているCatapultはFPGAベースのアクセラレータである。FPGAベースのアクセラレータは、専用ロジックと比べると性能は低いのであるが、処理ごとにFPGAを再構成して別の処理に使えるようにできるというメリットがある。可変性のあるFPGAが良いか、特定の処理にフォーカスしてカスタムLSIを作り、その処理だけを大幅に高速化する方が良いかは、データセンターの処理負荷に依存し、一概には言えない。

|
|
マイクロプロセサは処理の柔軟性が高いが、電力効率が低い。専用ハードウェアは電力効率は非常に高いが柔軟性には欠ける。DSPやFPGAはその中間である |
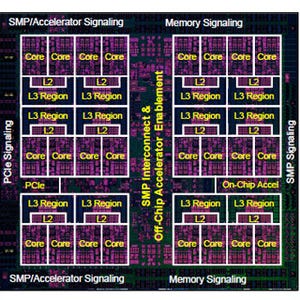
どこにどのようにアクセラレータを接続するかは、アクセラレータをアクセスするレイテンシやデータ移動のやり方、プロセサとアクセラレータの処理分担などに影響を与える。
その点で、ソフトの開発者やアクセラレータ使うシステムを運用する人たちは、密結合のアクセラレータを好む傾向がある。しかし、システム構成の自由度などの点から、緩やかな結合の方が望まれる。

|
|
アクセラレータをどこにどのように接続するかはソフトウェアにも影響する。ソフト開発者は密結合のアクセラレータを好むが、システム構成の観点からは、ある程度緩い結合の方が自由度が高い |