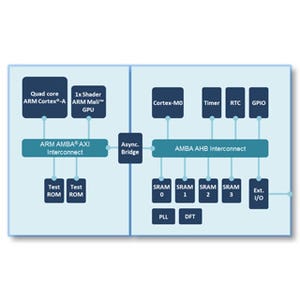
今回は実行ユニットがどの程度あるのかについては明確ではない(Photo07)。Cortex-A72の場合、Issueユニットは合計8ポートあり、このうちALUに4つ、FPU/NEONに2つ、Load/Storeに2つという割合になっていたが、ALUに関してはもう少し減っている可能性もある。ただしAGU(Photo08)に関してはDual IssueでLoad/Storeが搭載されているのは間違いないようだ。

|

|
|
Photo07:"ALUs"という表記なので、少なくともシングルではない事も間違いないのだが |
Photo08:ついにComplex Pattern Detectionがプリフェッチに登場した。また以前はデータキャッシュはPIPT(Physically Indexed Physically Tagged)だったのが、VIPT(Virtually Indexed Physically Tagged)に切り替わった |
周辺については、TLB廻りでアクセスの強化がなされたほか、L2キャッシュの性能改善が図られている(Photo09)。

|
|
Photo09:PTW(Page Table Wake)が同時に2つ実行できることで、より検索が高速化したとする |
こうした改善でどう性能が向上したか、という話であるが、まず同一プロセス・同一周波数で比較すると5~15%の改善が見られるとする(Photo10)。また、同じく同一プロセス・同一周波数で比較すると、消費電力が20%程度削減されているとする。ここでちょっとこちらの話につながるのだが、同じプロセスであってもCortex-A73のエリアサイズはCortex-A72よりも小さい。つまりトランジスタ数がより少ないという話であり、リーク電流に伴うスタティックな消費電力はおおむねこのトランジスタ数に比例するから、それだけで消費電力が下がるとする。それに加えて、諸々の省電力機構の実装や、なによりもデコード段を2-wayに減らした(デコード段がCPUパイプラインの中では一番電力を喰いやすい。もちろん広帯域のSIMDエンジンはまた別の話だが)ことで、ダイナミックな消費電力も削減できたことになる。

|

|
|
Photo10:メモリ帯域改善が15%ほどあり、これがNEONだと5%程度の性能改善に繋がっているということであろう。一方BBenchに関しては単にメモリアクセス以外の改善も効果的に作用していると思われる |
Photo11:削減の割合はものによって異なるが、おおむね20%ほどの削減が可能とされる。これに、16nm→10nmというプロセス変更の効果を加えると、Photo03の効果が期待できるという訳だ |
またエリアサイズの削減もコスト低減には重要な要素となる。Photo12は色々と誤解しやすい感じであるが、同一プロセスを利用した場合、Cortex-A73はCortex-A72と比べて25%ほどエリアサイズを削減できる。これに加えてプロセス微細化の効果で、より小さくなったという話である。

|
|
Photo12:逆に言えば、削減度合いが25%でもよければ、Cortex-A73を16FF+で利用できるという話でもある |
ところで、Cortex-A73はモバイル向けという話をしてきたのだが、もっと正確に書けば「モバイル向け"のみ"に特化したハイエンドコア」である。つまりサーバ向けのワークロードの事は考えていないし、利用するのも難しい。まずは性能の問題である。Cortex-A73の2-wayデコーダは、モバイルアプリケーションでのみCortex-A72を上回る性能を出せるが、サーバワークロードを含む、もっとデータ処理量の多いアプリケーションにおいては2-wayデコーダのCPU以上のものではなく、3-way以上のデコード能力を持つサーバ向けCPUには敵わない。
またCortex-A73では、サーバ向けCPUに求められるいくつかの信頼性に関する機能が省かれている。少なくともL1キャッシュに関しては、ECC保護が省かれているのは明らかにされている。これらはサーバ向けには必須であるが、モバイル向けには必須とは言えないからだ。他にもこうした信頼性に関する機能が省かれているものと思われる。
これに関しては、例えば派生型の形でECC保護機能付きのコアを出す予定は一切無く、あるいはCTL(これは別記事にて説明を行いたい)を利用してECCを付加させるという事も出来ないという。こうした用途には「Cortex-A72は(こうした用途には)いいコアだよ」(Ian Smythe氏)ということで、引き続きCortex-A72が利用されていくという形になるそうだ。