使いにくい点が改善された第2版が2013年6月に登場
OpenACCは、昨年11月の第1版の仕様では、色々と使いにくい点がある。第2版では、それらを改善している。

|
|
OpenACC2.0での主要な改善点 |
第1版では、カーネルプログラムの中では、他の関数の呼び出しはすべてインライン展開してカーネルプログラムに埋め込む必要があった。C言語では、関数呼び出しが多用されるので、これではカーネルプログラムが大きくなってしまい、好ましくない。
OpenACC2.0での第1の改良点は、NVIDIAのGPUが関数呼び出しができるようになったことを受けて、カーネルプログラムの中からの関数呼び出しと、関数のソースプログラムをメインのカーネルプログラムと独立にコンパイルすることが出来るようになった。これで普通のプログラミング環境に近づき、使いやすくなった。
関数のソースが別ファイルになる場合、C言語ではextern文で外部関数を宣言するが、OpenACCでは、extern宣言と関数定義の前に、#pragma acc routineという指示行を入れて別ファイルになっていることを示す。
そして、OpenACC2.0での第2の改良点は、CPU側で#pragma acc parallelを指示するだけでなく、その中で呼び出される関数の中でも#pragma acc parallelを使って2重のループ並列化を記述することが出来るようになったことである。
また、OpenACC 1.0でも並列化を行う場合、GPUで動かすグリッドに含まれるスレッドブロックの個数を指示することが出来たが、OpenACC2.0ではアクセラレータのタイプごとに、この値を変える構文が追加されている。これが3番目の改良点である。
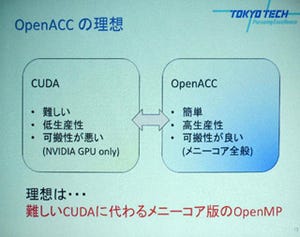
一方、7月30日に開催されたGTC Japan 2013で、東京工業大学(東工大)の星野氏が「OpenACCの理想と現実」という発表で指摘した構造体(Structure)が使えないという問題は、将来の検討課題として残っている。
OpenACCでは、並列化する部分に構造体を扱うコードを含むことができない仕様になっている。このため、元のプログラムが構造体を使っている場合は、構造体をばらす必要がある。そうすると、構造体の要素を参照する行は書き換えが必要になり、コードの書き換え量が非常に多くなってしまうという。
この点についてPoole氏に質問したところ、構造体には難しいケースがある。例えば、構造体のメンバはポインタで、実体のデータはポインタで指されたアドレスにある場合は、構造体だけをコピーしてもダメで、ポインタで指された実体データもコピーして、コピーされた構造体のポインタを書き換えるというディープコピーが必要になる。CRAYのコンパイラは、ディープコピーをサポートしており、将来のOpenACCで、このような機能を取り入れるべきかどうかを議論している段階とのことであった。
また、最近のサーバ用CPUは8~16コアを持ち、2ソケットのCPUに3台のGPUを接続するという計算ノードを使うスパコンが増えてきている。OpenACCは、基本的に1つのホストと1つのアクセラレータのモデルであり、1コアと1GPUしか使えないのかと質問してみた。現状では、基本的にはその通りであるが、PGIのコンパイラは、複数のデバイスと複数のデバイスタイプを扱えるようになっている。この機能を使って、GPUが1つのタイプのデバイスで、CPUコアは別のタイプのデバイスとして、それぞれのタイプの複数のデバイスを動かすことが可能になるという回答であった。ただし、これは、PGIの独自拡張機能であり、これらの機能が標準に取り入れられるのは次の仕様改定を待たなければならない。
このように問題点も残っているが、OpenACC2.0で、関数呼び出しと分割コンパイルがサポートされ、2重のループ最適化が可能になるなど、プログラム上の制約は減ってきている。OpenACC2.0対応のコンパイラをCRAYはすでに発表しており、CAPSやPGIも2013年末までには、発表の予定である。CPUとしてはx86とARMをサポートし、アクセラレータとしてはNVIDIA、AMD、IntelのXeon Phiをサポートしており、1つのソースコードで各種のシステムに対応できる状況が出来てきている。
これらは有料のコンパイラであるが、オープンソースの無料のコンパイラの開発も進んでいるという状況になっているという。

|
|
OpenACCをサポートするコンパイラが3社から出ており、x86とARM CPU、NVIDIA、AMD、Xeon Phiアクセラレータをサポートしている。また、OpenACC2.0準拠のコンパイラも近く3社のものが揃い、オープンソースのコンパイラの開発も進んでいる |
OpenACCを使えば、少し指示行を追加すれば大幅に性能を上げられるというほど簡単ではないが、前述の星野氏の例では、CUDA化する場合は8656行の書き換えに対して、OpenACC1.0のコンパイラでは3296行と4割弱の書き換えで、CUDA化の2/3程度の性能が得られている。
ただし、この書き換え行数は、構造体をばらすという作業が入っているので、将来、これが不要になれば、かなり、減少する可能性がある。また、将来は、コンパイラが改良され、よりCUDA化に近い性能が得られるという可能性もあり、CUDA化ほどの手間はかけられないが、かなりの性能アップは欲しいという場合には、OpenACCは有力な選択肢であろう。