OCR(光学式文字認識)は、かなり以前から存在するものだが、紙に書かれている文字(印刷や手書きも含む)を光学的に読み取り、文字データ化するものである。アンテナハウスから販売される「瞬簡PDF OCR」は、PDFやスキャナから取り込んだ紙の原稿データに対し、OCR処理を行うことができる。特徴として、2つあげられる。
- OCR処理の精度が高い
- Office(Word/Excel/PowerPoint)ファイルや透明テキスト付きPDFに直接変換
である。その他の主な機能は、以下の通りである。
- TWAIN(スキャナドライバ標準規格)対応のスキャナやPFU ScanSnapシリーズのスキャナから直接データを読み込む
- ADF(オートドキュメントフィーダー)対応スキャナからの連続読み込みが可能
- 対応するPDFバージョンは、1.3~1.7
- パスワードがかけられたPDFは、瞬簡PDF OCRでパスワードを入力することで読み込み可能
- 対応する画像ファイルは、BMP、JPEG、PNG、TIFF、JPEG2000、GIF
- OCRエンジンは日本語、英語に対応
システム要件は、Windows XP Homeエディション以上のOSに対応する(64ビットにも対応)。基本的にはOSが、動作する環境があれば十分である。できれば、メモリは多い方がよいだろう。インストールで、HDDの容量は260MB以上必要となる。特に厳しいものはない。価格は、CD-ROM版が6,930円、ダウンロード版が5,670円(いずれも税込みで、アンテナハウスオンラインショップでの販売価格)。アンテナハウスでは、15日間の体験版も提供しているので、まずは体験版を使ってみてもいいだろう。以下では、実際にスキャンで作成されたPDFデータで瞬簡PDF OCRを使ってみよう。
 |
図1 サンプルに使うPDF |
瞬簡PDF OCRで、PDFファイルを読み込む
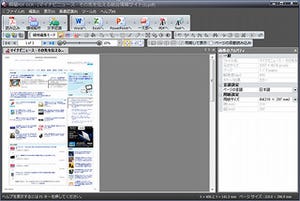
PDFは、Webなどでも使われる標準的な文書フォーマットである。表示用だけではなく、印刷用の入校データなどとしても使われることがある。そのようなPDFの場合は、文字データがアウトライン化されPDFから文字データをコピーすることができる。しかし、スキャンなどで作成されたPDFでは、すべてが図形データ化されており、文字データを取り出すことができない場合がある。そのような場合でも、瞬簡PDF OCRならば文字データ化できる。まずは、瞬簡PDF OCRを起動したのが、図1である。
 |
図2 瞬簡PDF OCRのメイン画面 |
この左側の大きなペインに、PDFをドラッグ&ドロップする。この時点で、PDFの分析などが行える。
 |
図3 PDFファイルを読み込み |
まずは、ここでは、何もせずにWordに変換してみよう。メニューバーの[Wordへ]をクリックする。領域分析や認識処理などが行われる。
 |
図4 認識処理中 |
そして、Wordが起動し、OCRエンジンによって読み込まれたWordデータが表示される(図5)。
 |
図5 Wordデータに変換 |
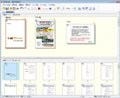
よく見ると、表の最下行に余計な罫線が入っている。また、グラフの一部の文字を読み込もうとしたと思われる箇所がある。本文については、かなり正確に読み込めている。あとは、フォントサイズに乱れがあるが、ここまでできていれば、手入力するよりは作業が大幅に省力化できるはずだ。色なども正しく反映されている。Wordを閉じて、瞬簡PDF OCRを表示すると、図6のようになっている。
 |
図6 変換後の瞬簡PDF OCR |
PDF上に、領域の分析が行われている。瞬簡PDF OCRが認識する領域は、以下の4つである。
- 文字(縦書き):ピンクの部分
- 文字(横書き):赤の部分
- 表:緑の部分
- 画像:青の部分
この認識に従い、OCRエンジンが文字などを認識する。
少しだけ人の手で調整する
上述の4つの領域の認識が正確であればあるほど、変換後のデータが正確になる。そこを、ほんの少しではあるが、人の手をかけるとよい。実際にやってみよう。PDFを読み込んだら、[領域解析]をクリックする。同じPDFであれば、図6と同じような領域分析になる。ここでは、図の部分が、複数の異なる領域と認識されてしまう。そこで、不要な領域は削除し、図7のようにする。
 |
図7 領域を整理 |
やったことは、不要な領域設定を削除し、グラフ全体を1つの画像領域とした。この状態で、Wordデータに変換したのが、図8である。
 |
図8 領域を調整した後に変換したWordデータ |
図5と比較すると、グラフもきちんと表示されている。これだけのことだが、前処理を行うことで、変換効率を上げることができる。使い込む過程で、工夫していけばよいであろう。最後にテキスト変換を行ったのが、図9である。
 |
図9 テキストに変換 |
Officeデータに直接変換するのも便利ではあるが、この方法も覚えておきたい。場合によっては、後処理がしやすいこともある。瞬簡PDF OCRは、強力なOCRエンジンがなんといっても魅力である。従来のOCRに不満を感じているのであれば、ぜひ試してみていただきたい。