4つのパネルを聞いて
演算器よりもデータの移動の方がエネルギー消費が大きいので、データ移動を極力抑えるローカリティが重要という点では認識は揃っている。しかし、細粒度の非同期実行モデルにすれば、ローカリティを高めるような実行順序に変えることができるというようなアイデアはあるが、誰が、どのようにローカリティを引き出すのかについては、まだ、具体案が乏しい感じである。
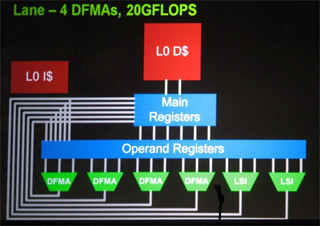
また、実行モデル、ひいてはハードウェアの基本的なアーキテクチャに関しても、GPUのようなSIMT(Single Instruction Multiple Thread)モデルを改良していくことで乗り切れると考えているNVIDIAなどと、Codeletを多数のシンプルなCPUコアで非同期実行する実行モデルを推進する派がある。
GPUはプログラミングの困難さの改善が続いており、また、アルゴリズムの工夫でGPUで性能が出る問題が増加しつつあるが、やはり、アルゴリズムやコードの大幅書き直しという問題があり、移行は容易ではないというハンディがある。
一方、細粒度非同期実行は、BG/QプロトタイプがGPUに勝るMFlops/Wを実現しており、必ずしもGPUコンピューティングに比べてエネルギー効率が悪いとは言えない。コンパイラとアーキテクチャの改善で自動的に高度なCodelet並列が実現できれば、コード変更のハードルはGPUに比べてずっと小さくなる。しかし、Codelet並列でどれだけ性能が出せるかについてはあまり実績が無く、まだ、アカデミックな研究の範囲を出ていない。
消費電力に関しても明確な解はなく、実行モデルに関しても大きく2つの候補があり、どちらが主流になるのか分からない状態であり、まだ、Exascaleの行方は混沌としているという印象であった。
しかし、少なくともDARPAは4チームを選んで、Phase-1の4年間で技術的な方向付けを行い、Phase-2の4年間で実証システムを作るというやり方をしている。日本の京スパコンプロジェクトのように基礎的な検討をほとんどやらないで、ぶっつけ本番で作れるものを作るというのと比べるとまっとうなやりかたである。と思っていたのであるが、最後のパネルでSterling教授は、ミッションクリティカルな機関(DARPAなどを指す)は、
- 長期的なリサーチの必要性は理解しているが
- それを以前にやっていないので、キャッチアップのためにショートタームの開発に資金を出さざるを得ない
- 1に戻る
というモードに陥っていると批判していたので、タイムスケールは違うが感じ方はいずこも同じようである。