Disruptive Technologies for Ubiquitous High Performance Computing
このパネルは、モデレータはローレンスバークレイ国立研究所のJohn Shalf氏、パネリストはサンディア国立研究所のRichard Murphy氏、IntelのJohn Gustafson氏、NVIDIAのBill Dally氏、MITのAnant Agarwal氏というメンバーである。

|
|
左からShalf、Dally、Gustafson、Murphy、Agarwalの各氏 |
IntelのGustafson氏は、現状はTFlopsに5kW必要としているが、Exaではこれを20W程度にしなければならない。PetaからExaへの1000倍は、過去の1000倍とはまったく違うと前置きをして、消費電力を減らす一例として、Near Threshold Logic、DRAMもRASでページ全体をアクティブにするのではなく、必要な一部だけをアクティブにするなどの方法を挙げた。
チップ上のコア間の信号伝送に必要なエネルギーは10pJ/Byteであるが、チップ間は100pJ/Byte、現状のメモリは1.5nJ/Byteを必要とする。したがって、データローカリティが重要。また、微細化、電源電圧の低下で中性子などによるエラーが増加するので、エラー検出から、故障個所の切り離し、システムとしてのリカバリなどが重要になると述べた。
サンディア研のMurphy氏は、データローカリティについては現状ではMPIがベストの解であるが、これはプログラマがローカリティを直接書いており、 Exascaleのプログラムの解にはならない。また、グラフ問題ではローカリティが実現できないことも分かっている。
したがって、データをプロセサの近くに持ってくるという発想ではなく、計算処理をできるだけデータの近くで行うという考え方が必要と説く。

|
|
サンディア研のParallel-Xと他の実行モデルの比較。赤字の部分が他のアプローチと異なる部分 |
このサンディア研のParallel-Xと呼ぶ実行モデルでは、プログラムを独立に実行できるCodeletと呼ぶスレッドよりも小さな単位に分解し、超多数のCodeletの中から実行できるものをドンドン実行していくという方法で高い並列実行性能を実現しようというアプローチをとる。また、Codeletなどの実行単位間の連携には通常のBSP(Bulk-Synchronous Parallel)モデルではなく、Light Weightのコントロールオブジェクトを使う。
MITの教授で並列コンピュータ研究の草分けの1人であるAgarwal教授はAngstrom Projectの考え方を説明した。Agarwal教授はタイルプロセサのTILERAの創立者でもあり、Angstromにはタイルの考え方が取り入れられている。
Angstromでは、コンピューティングの各階層で、エネルギー、性能、セキュリティ、抗坦性(Resiliency)を自分で認識するSEECとHWとSWの物理的な分配によるローカリティを探索するFactoringという2つの概念が中心となっている。

|
|
AngstromのSEECは観測→決定→動作のループで最適化を行う |
Exascaleに対して、プロセサとしては11nmプロセスを使い1000コアのタイルプロセサでピーク性能5TFlopsを50W(50mW/Core)で実現する。そしてハードウェアとOSの間にSEEC Architecture APIを設け、ここでエネルギー消費やデータ移動などを最適化する。また、OSもSelf Awareで各部の動きをモニタしながら調整を行いフィードバックをかける。プロトタイプで、指定されたレベルの性能を維持しながら電力を減らしていく様子を示した。
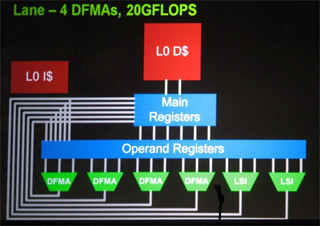
Dally教授は基調講演で述べたEchelonを再度簡単に説明し、EchelonのDisruptive(過去から飛躍し、不連続)なテクノロジは次のスライドに示す4つの点にあると述べた。

|
|
NVIDIAのEchelonの革新的なポイント |
ローカリティに関しては、プログラミングシステムで、階層的グローバルアドレスを使用しローカリティを抽象化して表現する手段を提供する。そして、アーキテクチャでは消費エネルギーを指定したバンド幅の提供、再構成可能なメモリ階層、階層的グローバルアドレスを提供する。また、100億スレッドを実行する細粒度並列性に関しては、GPUのSIMT実行の改善、抗坦性についてはチェックポイントデータの削減と検算などの有効活用をあげた。